
아래 블로그에 대한 내용을 정리한 글입니다.
- https://dol9.tistory.com/281
- https://dol9.tistory.com/282
- https://www.youtube.com/watch?v=tU2pHxLh4ZU
카프카에서 Purgatory가 사용될 때
컨슈머
컨슈머에서 메시지를 가져올 때 성능 개선을 위해서 메시지를 배치로 묶일 때 까지 대기를 하게 된다.
- 컨슈머가 브로커로부터 레코드를 읽어올 때 데이터의 최소량(byte 단위)이 되지 않았을 때
- 카프카가 컨슈머에게 응답하기 전 충분한 데이터가 모일 때까지 기다릴 수 있는데 시간을 만족하지 않았을 때
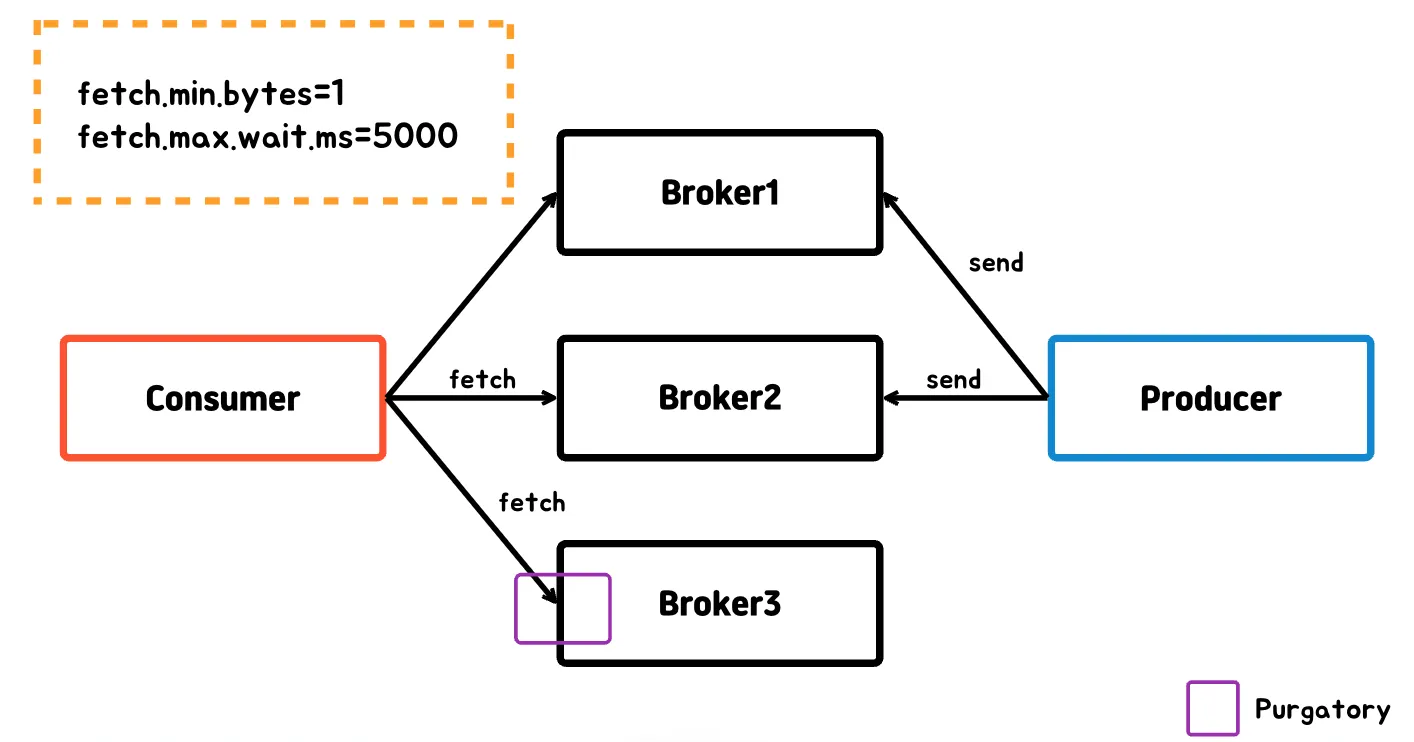
이 때 컨슈머가 보낸 요청이 머무는 것을 Purgatory라고 하며, Purgatory에서 벗어나는 방법은 요청 조건에 만족하거나, 지정한 시간이 흘러 timeout이 발생하면 벗어날 수 있다.
컨슈머가 리벨런스가 될 때

컨슈머가 그룹 코디네이터에게 하트비트를 보내지 않은 채로 session.timeout.ms만큼 지나게 되면 컨슈머는 죽은 것으로 간주하고, 파티션 리밸런싱을 진행하는데 이때도 Purgatory가 사용된다.
- session.timeout.ms는 컨슈머가 하트비트를 보내지 않을 수 있는 최대 시간을 결정하기 때문에 session.timeout.ms와 heartbeat.interval.ms 는 보통 함께 변경된다.
- heartbeat.interval.ms는 하트비트를 몇초마다 보낼지를 의미합니다. (session.timeout.ms의 1/3 값으로 설정함)
프로듀서
acks=all or -1를 적용하게 되면 브로커는 모든 In-Sync-Replica에 메시지가 전달되어야 프로듀서에게 성공했다는 응답을 보낸다.
- replication factor에 따라서 모든 팔로워를 체크하는 것이 아니라 min.insync.replicas 옵션에 맞춰지는걸 다시한번 기억하자
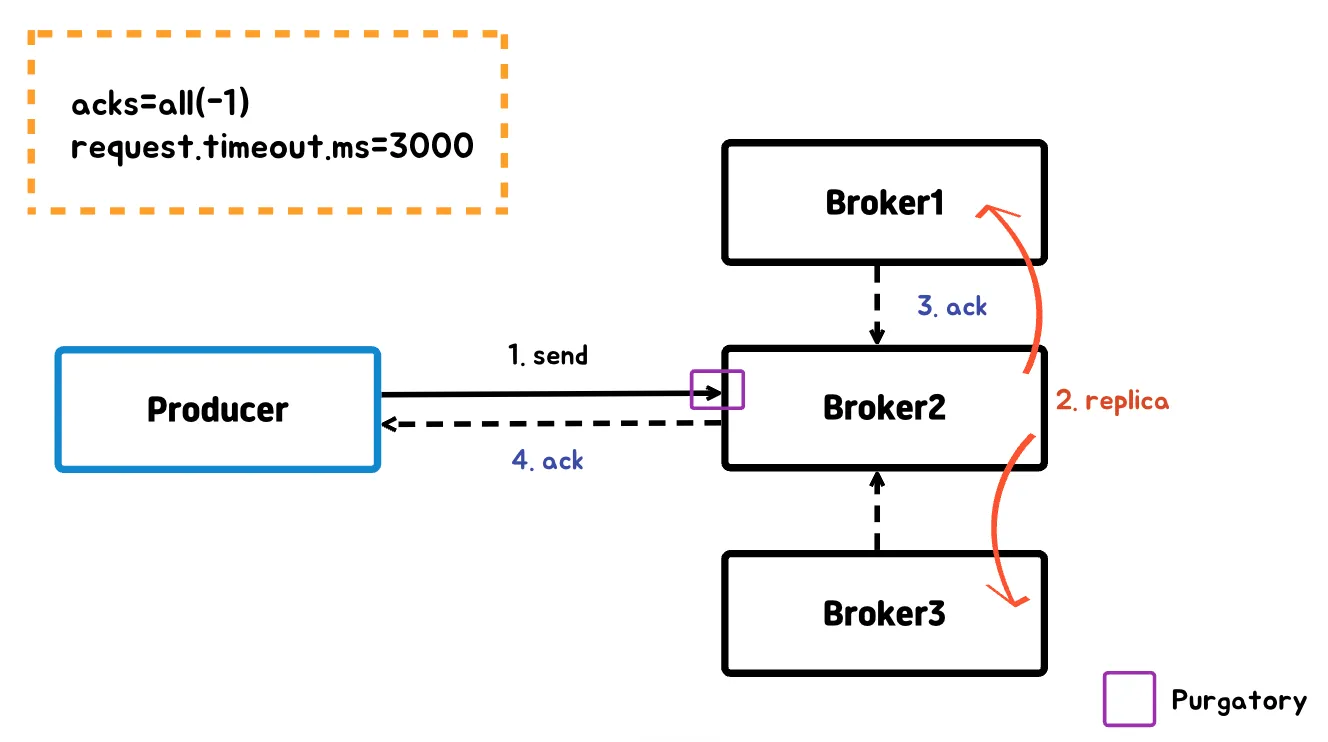
프로듀서에게 성공했다는 응답을 보내기 위해서는 모든 broker에 복사될 때까지 기다려야 하는데, producer의 send 요청이 broker에 머물러 있는걸 purgatory라고 한다.
기존 Kafka purgatory 디자인
timeout을 체크하는 Timer와 purgatory에 있는 요청이 조건을 만족하는지 관리하는 watcher가 존재한다.

Expire task(요청을 만족하거나 Timeout이 지정된 요청) 요청이 오면 Timer와 Watcher에 등록이 되게 된다.
- 파티션에 메시지가 추가될 때마다 Watcher를 이용해 조건을 만족하는지 판단하고 Timer에서는 주기적으로 peak에서 Expire 할 task인지 판단한다.
Timer와 Watcher 각각에서 Expire된 task를 바로 지우지 않고 Reaper thread가 일정 주기로 전체를 순회하면서 완료된 task를 지워주었다.
- Reaper thread가 순회하는 주기가 짧으면 메모리 관리는 되지만 전체 데이터를 순회하고 판단하는 연산으로 인해 성능 저하가 발생한다.
- 주기가 길면 메모리 관리가 잘 되지 않아 OOM이 발생할 수 있다.
Expire task가 급격하게 추가되고 조건이 바로 만족된 경우
- Expire task를 추가하고 삭제는 빈번하게 발생하는데 Delay Queue(Heap)의 시간 복잡도는 O(log n)이였다.
- Kafka는 Timer에 Expire task를 추가 삭제할 때 O(1)을 목표로 하였으며, Watcher의 task와 Timer에 추가되는 task를 연결하여 Watcher에서 삭제시 Timer에서도 삭제할 수 있는걸 목표로 했다.
개선된 Timer
Client에서는 Expire Task를 등록하는 API인 start와 등록된 Expire Task를 삭제하는 stop이 있다.
Timer 내부에서는 매 Time Unit이 1초라고 가정했을 때 1초마다 완료되지도 않았고 timeout이 되지도 않은 timer를 순회한다.
- Expire Task를 탐색하는 동작을 Per-tick bookkeeping
- 찾은 Expire Task를 처리하는 동작을 Expiry processing이라고 한다.
- Expiry processing 동작은 client가 start API로 전달한 callback을 실행하거나 미리 정의된 로직이 수행된다.
scheme 1. Unordered Timer List
Expire 순서 상관없이 정렬되지 않은 타입 리스트

- 추가 작업은 O(1), Per-Tick은 Expire된 Task를 찾아야 되기 때문에 O(n)
scheme 2. Ordered Timer List
Expire 순서로 정렬된 타입 리스트

- 추가 작업은 Expire 순서로 정렬하기 때문에 O(n), Per-Tick은 Head를 읽어오면 되기 때문에 O(1)
scheme 3. Tree-based Timer
저장하는 자료구조를 balanced binary tree로 변경

- B-Tree 구조라서 start는 O(log n), Per-Tick은 Peak 부분을 가져오면 되기 때문에 O(1)
scheme 4. Simple Timing Wheels
등록할 수 있는 timer의 최대 크기는 time unit에 의존하게 된다.
- 지금 그림에서는 Expire Time을 Max로 8초를 줄 수 있는 원형 큐 이다.

- 1초 마다 Per-Tick이 버킷을 하나씩 움직인다고 생각하면 된다. [Per-Tick → O(1)]
- 현재는 3초짜리 task와 7초짜리 task들이 있는 것을 볼 수 있다. [start → O(1)]
- 정렬되어 있지 않은 List 형태
성능이 좋지만 interval이 커질수록 원형 큐에 사이즈는 비례해서 커지기 때문에 메모리 사용량도 증가하며 계속해서 커질 수 있는 경우 OOM까지도 발생할 수 있다. (즉, 사이즈 제한이 존재한다.)
- 서비스에서 최대 interval를 알 수 있는데 크지 않다면 괜찮다.
scheme 5. Hashing Wheel with Ordered Timer List
4번에서는 버킷에 최대 크기가 Expire Time에 최대 시간과 연관이 깊었다.
- 시간 제한 없이 두기 위해서 최대 값이 16인 경우 한 바퀴 돈 다음 저장한다.

- 버킷에 추가될 때 리스트에 정렬되어 저장되기 때문에 start는 O(n) 이며, Per-Tick은 O(1) 이다.
- 평균 start에 시간 복잡도 O(1)을 가지기 위해서는 n < buffer 크기이고 timer가 잘 분산되어야 한다.
scheme 6. Hashing Wheel with Unordered Timer List
scheme 5와 비슷하지만 timer 저장을 Unordered List에 한다.

- 정렬이 일어나지 않기 때문에 추가될 때 start는 O(1)이며 Per-Tick은 버킷은 움직이지만 정렬되지 않은 리스트에서 찾아야 되므로 O(n)이다.
scheme 7. Hierarchical Timing Wheel
time-unit이 서로 다른 timing wheel을 여러 개 두어 timer 저장 공간을 아낄 수 있다.

- 실제 Expiry Processing은 가장 time unit이 작은 timing wheel에서만 실행한다.
모든 timing wheel에 timer를 저장하지 않고 time interval에 적합한 최상위 timing wheel 하나에 저장한다.

- 높은 level에 timing wheel은 아랫단계의 timeing wheel로 보내기만 하는데 아랫 단계로 보내는 연산을 migrate라고 부른다.
🤔 1시 30분 40초 뒤에 expire 될 timer가 등록된다면?
time interval이 한 시간 단위인 timing wheel의 1시간 slot에30분 40초의 timer 저장한다.

- 한 시간 단위 timing wheel의 tick이 실행되어 Per-tick이 위에서 등록한 1시간 slot을 체크하면 30분 40초 timer는1 분단위의 timing wheel의 알맞은 slot에 40초 timer 저장하게 된다.
각각의 타이머 스키마 시간 복잡도
| Schema | Name | Start | Per-Tick |
| 1 | Unordered Timer List | O(1) | O(n) |
| 2 | Ordered Timer List | O(n) | O(1) |
| 3 | Tree-based Timer | O(log n) | O(1) |
| 4 | Simple Timing Wheels | O(1) | O(1) |
| 5 | Hashing Wheel with Ordered Timer List | O(n) worst O(1) average |
O(1) |
| 6 | Hashing Wheel with Unordered Timer List | O(1) | O(n) worst O(1) average |
| 7 | Hierarchical Timing Wheel | O(m) m: number of wheels |
O(1) |
현재 Purgatory 모습
Timer는 Hierarchical Timing wheel로 변경하여 추가시 wheel에 개수만큼 O(m) 걸리며 Per-Tick은 O(1)으로 처리할 수 있다.

그리고 Watcher의 task와 Timer task를 참조하는 형태로 만들었다.
- Watcher에서 조건을 만족해 삭제가 진행되면 Timer에서 바로 삭제할 수 있도록 하였다.
Expire task를 어떻게 구성했길래 Watcher의 task와 Timer의 task를 연결했을까?

- 왼쪽에는 Expire task가 실제 구현된 코드가 있다. (토픽 생성, 리더 투표, 메시지 fetch, 토픽 삭제 등)
- TimerTask를 extends 한 DelayedOperation이 있고 DelayedOperation을 extends 한 Delayedxxx가 있다.
- TimerTask의 멤버 변수로 TimerTaskEntry가 존재한다.
TimerTaskEntry를 이용하여 TimerTask의 양방향 연결 리스트를 만들 수 있다.

Timer의 Expire task가 추가될 때 알맞은 slot 인덱스를 찾고 TimerTaskList 형태로 task가 추가된다.
Timer
기존에 Timer가Java의 DelayQueue로 구현했었는데 DelayeQueue가 여기도 사용된다.

- 기존과 다른 점은 task마다 한개씩 추가되는 형태가 아니라 TimerTaskList 단위로 최대 Timing wheel slot 개수만 큼 추가 된다.
- 하나의 TimerTaskList에 존재하는 task들은 해당 level Timing wheel에서 동일한 시간의 expire이기 때문에 가능하다.
Watcher
Watcher는 DelayedOpeartion type으로 ConcurrentLinkedQueue 자료구조를 이용하여 task를 저장된다.

- 배열로 되어있는 WatcherLists에는 Map 자료구조들이 저장되어 있다.
- 이 Map의 Key는 "[Topic name]-[Partion Number]" 문자열을 해싱한 값의 WatcherLists.size() 나머지 값이며 Value로 ConcurrentLinkedQueue가 연결되어 있다.
- 샤딩을 위해서 이러한 Key값을 가진다.
Watcher에서 조건이 만족되면 Timer에서 어떻게 바로 지울 수 있을까?

Watcher에서 조건을 만족한 DelayedOperation은 TimerTask로 형 변환이 가능하다.
- TimerTask에는 멤버 변수로 TimerTaskEntry가 있기 때문에 TimerTaskList에서 본인 것만 삭제를 하면 Timer와 Watcher 두 곳 모두 삭제할 수 있다.
반대로 Timer에서 지워진 task는 Watcher에 바로 지우지 않고 Reaper Thread가 주기적으로 실행하면서 조건이 만족되면 정리를 시작한다.

Timer는 자기꺼만 삭제가 될텐데 Watcher에 등록된 task와 Timer에 등록된 task 개수 차이가 1000(default) 이상이면 reaper thread가 Watcher의 Expire Task를 삭제한다.
'Kafka' 카테고리의 다른 글
| 카프카 스트림 처리 (0) | 2025.02.17 |
|---|---|
| 컨슈머 랙(LAG) (1) | 2024.12.02 |
| Kafka ISR(In-Sync-Replica) (1) | 2024.11.15 |