
책을 읽고 이전 글을 작성하면서 ISR 개념에 대해서 학습하고자 정리한 내용입니다.
카프카 프로듀서: 카프카에 메시지 쓰기
프로서 개요애플리케이션이 카프카에 메시지를 써야하는 상황들감사 혹은 분석을 목적으로 하는 사용자 행동 기록성능 매트릭 기록로그 메시지 저장 (ELK 스택에서 Filebeat Kafka output 설정등)스마
uhanuu.tistory.com
Kafka Replication
Kafka에서는 고가용성을 위하여 Replication이란 기능을 제공합니다.
- Topic의 Partition들을 다른 브로커들로 복제하는 것을 의미
- 동일한 데이터를 여러 브로커에 기록하여 데이터 손실을 방지
Replication factor(기본값 1)를 통해서 Topic을 이루는 Partition을 replication할 수 있다.
- replication-factor의 경우, broker(node) 수를 넘지 못한다.
- replication-factor의 수가 증가할 수록 다른 노드간 복제를 위한 리소스 증가와 디스크 사용량이 증가하기 때문에 적절하게 조정해야 한다.

- 브로커 손실과 복제 오버헤드 간에 적절한 균형을 제공하므로 일반적으로 3의 복제 계수를 사용한다.
토픽을 생성할 때 replication-factor의 수를 지정할 수 있습니다.
kafka-topics.sh --bootstrap-server localhost:9092 --replication-factor 1 --partitions 3 --topic test --create- partitions를 통해서 생성할 Topic의 Partition 수를 지정할 수 있다.
- replication-factor를 통해서 생성할 Topic의 replication factor 수를 지정할 수 있다.

replication-factor가 3인 Topic을 생성하게 된다면 아래와 같은 형태로 구성 됩니다.

파티션에서 Leader 그리고 Follower
Leader가 Producer의 메시지(데이터 원본)를 전송받으면 Follower는 리더 파티션에 데이터를 복제합니다.
Partition 4, Replication factor가 3으로 설정된 Topic

데이터 일관성을 보장하기 위해서 모든 Producer와 Consumer 요청은 Leader replica만 처리하며 데이터를 저장한다.
- Follower replica가 Leader replica로부터 데이터를 복제하는 시간차 때문에 Leader replica와 Follower replica 간에 오프셋차이가 발생할 수 있다.
ISR(In-Sync-Replication)
ISR(In Sync Replication) 은 정상적으로 복제를 보장하는 replication group 을 뜻하는데 Leader replica와 Follower replica들이 모두 싱크된 상태(메시지 복사가 잘 되어있는 Follower들의 구성)를 의미합니다.
Leader replica에 문제가 생겨 중단되는 경우 Follower replica 중 하나가 해당 Partition의 새로운 Leader replica로 선출된다.
- 이 때 제대로 데이터를 복제해 오지 못한 Follower replica가 존재할 수 있는데 해당 Follower replica를 제외한 나머지 Follower replica 중에서 Leader replica를 선출하기 위해 ISR 목록에서 선정한다.

- ISR은 토픽/브로커 config인 min.insync.replicas 를 통해 결정되며, producer 의 config 인 acks 와 연관이 깊다.
이번에 이야기한 replication-factor는 min.insync.replicas와 acks=all를 같이 사용한다.
이전 글에서 설명했으므로 옵션에 대해서 간단히 설명하면

acks=all을 설정하면 Producer에게 성공을 응답하기 위해 리더 파티션을 포함해서 min.insync.replicas의 개수만큼 팔로워 파티션의 데이터가 복제되었는지 확인한다.
- min.insync.replicas의 기본값은 1이므로 리더파티션 하나만 응답하기 때문에 2이상 지정해줘야 acks=all을 사용하는 의미가 있다. (kafka 3.0 이상부터는 기본값이 acks=all)
ISR 간 동기화 방식
ISR 간 동기화는 Push가 아니라 leader가 메시지를 저장했으니 가져가서 복제하라는 Pull 방식으로 동작합니다.
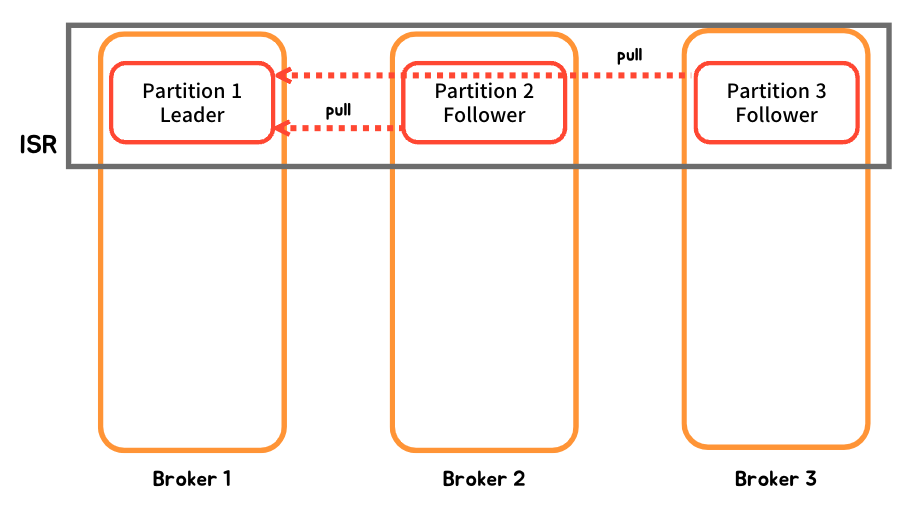
ISR에서 Follower 선출 방법
- Leader는 메시지를 Commit할 시기를 결정한다.
Leader 자기 자신이 장애 시 Follower에게 Leader를 넘길 수 있는 상태를 체크하고 목록을 구성합니다.
- 정확히는 해당 Partition의 Leader가 떠있는 Broker가 ISR을 관리합니다.
Leader는 아래 설정에 해당하지 않는다면, Follower를 탈락시키고(ISR 그룹에서 제외) 새로운 Follower를 찾아 메세지를 복제 시킵니다. (메세지를 복제하면 ISR 목록에 편입되며, Commit도 진행 되게 됩니다.)
- replica.lag.max.messages: follower들이 최대 몇 개까지 복제가 늦어져도 되는지 설정
- replica.lag.time.max.ms: follower들이 max message를 벗어났을 때 max message 보다 안쪽으로 들어올 때 까지 기다리는 최대 시간 설정
Follower가 복제하고 있는지 알고 목록을 구성하는 방식을 이해하기 위해서 Message Commit을 알아봅시다.
Message Commit(High Water Mark)
ISR 목록의 모든 Replicas가 메시지를 성공적으로 가져오면 Committed되며 Consumer는 Committed 메시지만 읽을 수 있습니다.

- High Water Mark: 가장 최근에 Committed 메시지의 Offset 추적하기 위해 사용되며 replication-offset-checkpoint 파일에 체크포인트를 기록합니다.
아래 그림처럼 replica.lag.max.messages를 4라고 가정
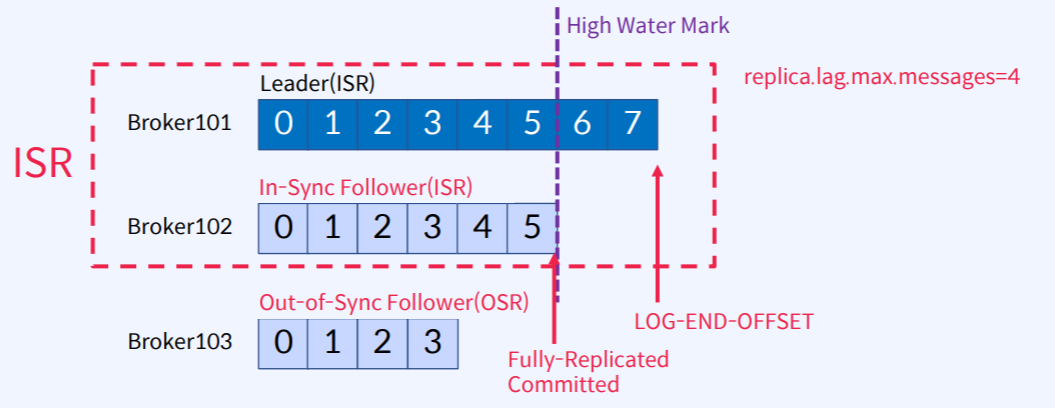
- Leader의 LOG-END-OFFSET=7
- High Water Mark=5인데 Follower 중에서 Leader에 데이터를 가장 잘 복사한 애가 Fully-Replicated 되고 Commit까지 한 위치를 뜻합니다.
- Broker103은 Leader와 Offset이 4만큼 차이나기 때문에 replica.lag.max.message=4 옵션에 해당하게 됩니다.
이 때 상황을 이야기하면
우선 Leader는 ISR이 되며 Leader의 데이터를 가장 잘 복제하고 있는 Follower는 In-Sync Follower(ISR)가 되고 replica.lag.max.message에 해당하는 Follower는 Out-of-Sync Follower(OSR)이 됩니다.
- Leader에 장애가 발생하면 ISR 중에서 Leader의 데이터를 가장 잘 복제하고 있는 Follower를 새로운 Leader로 선출합니다.
⛔️ replica.lag.max.messages로 ISR 판단시 나타날 수 있는 문제점
메시지가 항상 일정한 비율로 전송되면 지연되는 경우가 없어 ISR들이 정상적으로 동작하고 메시지 유입량이 갑자기 늘어날 경우 지연으로 판단하고 OSR(Out-of-Sync Replica)로 상태를 변경 시키게 됩니다.
Follower들이 잘 동작하다가 잠깐 지연만 발생해도 replica.lag.max.messages 옵션을 이용하면 OSR로 판단하게 되는 문제가 발생하면서 불필요한 에러와 재시도를 유발시키게 됩니다.
🤔 따라서 replica.lag.time.max.ms로 판단해야 합니다.
Follower가 Leader로 Fetch 요청을 보내는 Interval을 체크합니다.
- replica.lag.time.max.ms = 10000 이라면 Follower가 Leader로 Fetch 요청을 10000ms 내에서만 요청하면 정상으로 판단
즉, ISR을 제외하고 편입을 하는건 replica.lag.max.messages, replica.lag.time.max.ms 두 가지 옵션에 의해서 생기게 되며 replica.lag.time.max.ms시간으로 판단하여 ISR에서 제외되도록 하자.
Follower가 너무 느려서 replica.lag.time.max.ms를 넘어간다면?
- Leader는 ISR에서 Follower를 제거하게 됩니다.
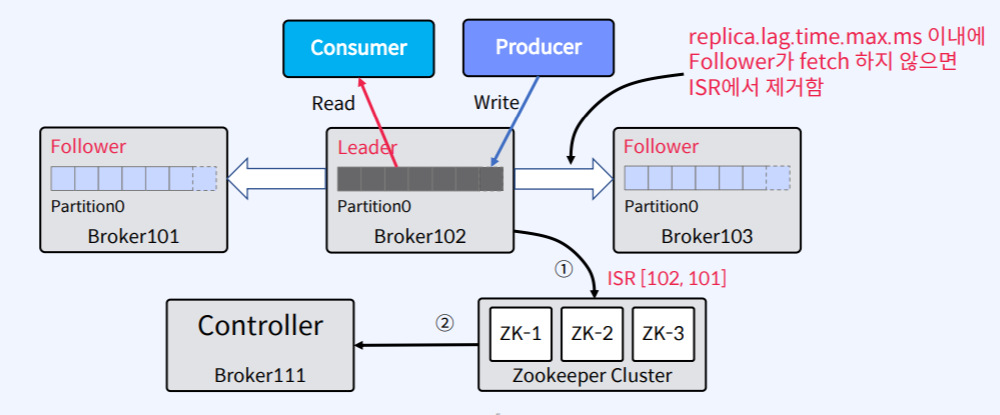
이 때 Leader는 Zookeeper에 Partition Metadata에 대한 변경 사항을 알려주고 전달 받은 Zookeeper는 Broker중에 하나인 Controller라고 하는 곳으로 변경 사항을 다시 보내주게 됩니다.
- 이 후 Controller에서 Partition Metadata에 대한 변경 사항에 대해서 나머지 Broker들에게 알려주는 방식으로 동작합니다.
예제들은 여기에서 가져왔습니다.
Producer가 Message 3개 보냈을 때를 가정해보면 제일 먼저 리더가 Message 3개를 받아 저장하고 Follower는 Pull을 하여 메세지를 복제 합니다.

- Follower1은 2개 Follower2 는 1개를 복제 했다고 하면 M1(첫 번째 메세지)은 준비 되었다고 하면서 High Water Mark가 찍하게 됩니다.
메세지가 5개가 더 들어와서 leader는 8개의 메시지를 가지고 Follower1은 메세지를 복사했지만, Follower 2는 메시지를 복사하지 못했습니다.

- replica.lag.max.messages, replica.lag.time.max.ms에 설정한 값에 의해서 Leader는 Follower 2를 ISR 그룹에서 제외 시킵니다.
다시 Follower2 가 메세지를 복제하면 ISR 목록에 편입되며, Commit도 진행 되게 됩니다.
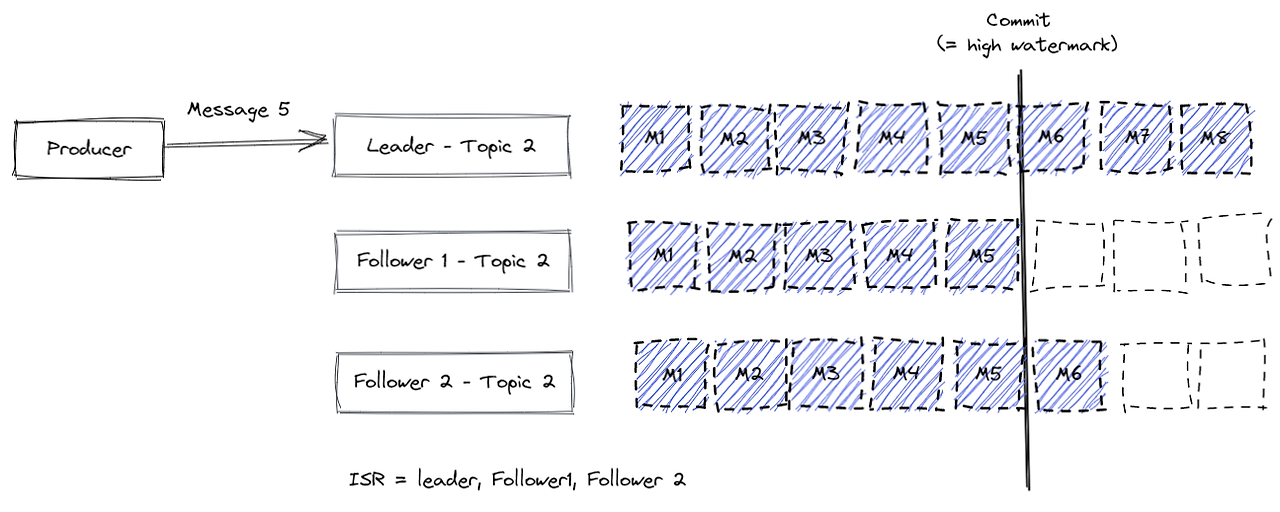
이러한 메시지 선출 방식이 존재하는 이유
Committed 메시지는 모든 Follower에서 동일한 Offset을 갖도록 보장하기 때문에 어떤 Replica가 Leader인지에 관계없이 (장애가 발생하더라도) 모든 Consumer는 해당 Offset에서 같은 데이터를 볼 수 있습니다.
- Broker가 다시 시작할 때 Committed 메시지 목록을 유지하도록 하기 위해 Broker의 모든 Partition에 대한 마지막 Committed Offset은 replication-offset-checkpoint라는 파일에 기록됩니다.
Leader epoch
Leader가 죽었을 때 새로운 리더가 돼면서 epoch가 바뀌게 됩니다.
Broker 복구 중에 메시지를 체크포인트로 자른 다음 현재 Leader를 따르기 위해 사용되며 새 Leader가 선출된 시점을 Offset으로 표시합니다.
- leader-epoch-checkpoint 파일에 체크포인트를 기록한다.
- Controller가 새 Leader를 선택하면 Leader Epoch를 업데이트하고 해당 정보를 ISR 목록의 모든 구성원들에게 보낸다.
기존의 Leader가 장애가 발생하였다고 하고, 들어와있던 message가 commit되지 않은 상태
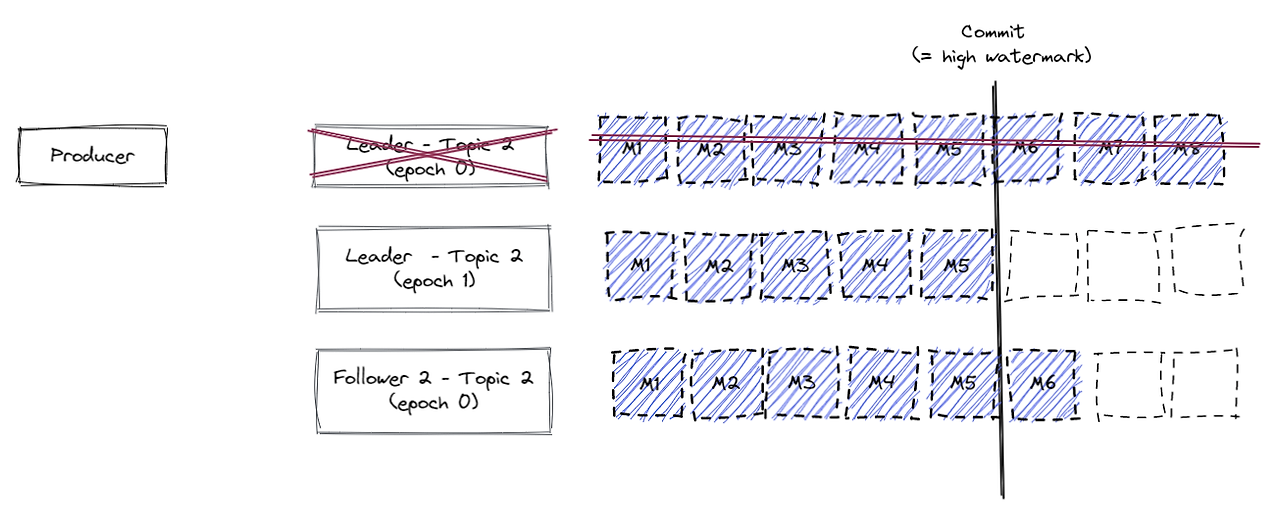
- 새로운 Leader가 선출 되면서 기본에는 epoch0 이였지만 epoch = 1로 바뀌게 됩니다.
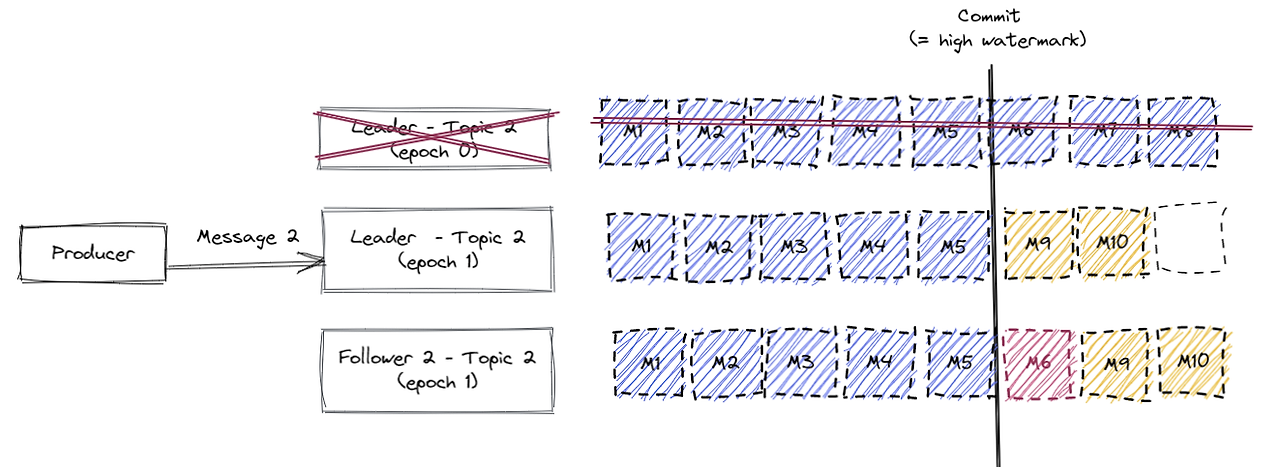
commit되진 않았지만 Follower2에 이전 leader에게 복제한 m6가 복제되어 있는데 새로운 leader에서 온 메세지가 아니기 때문에 m6메세지는 삭제 됩니다.

- 그리고 새로운 leader를 맞이 했으므로 Follower2는 epoch가 1로 올라 갑니다.
이 때 새로운 leader에 메세지가 2개가 들어오면 leader에 데이터가 써지고 새로운 epoch 를 가진 Follower2는 이 leader가 가진 메세지를 복제 합니다.
ISR은 Kafka에 가용성을 이야기할 때 중요한 내용이며 leader-follower, ISR, commit, leader epoch으로 가용성을 유지 하게 됩니다.
📚 reference
- https://learn.conduktor.io/kafka/kafka-topic-replication/
- https://docs.confluent.io/platform/current/installation/configuration/topic-configs.html#min-insync-replicas
- https://damdam-kim.tistory.com/17
- https://magpienote.tistory.com/253
- https://velog.io/@hyun6ik/Apache-Kafka-In-Sync-Replicas#isr%EC%9D%80-leader%EA%B0%80-%EA%B4%80%EB%A6%AC
'Kafka' 카테고리의 다른 글
| 카프카 스트림 처리 (0) | 2025.02.17 |
|---|---|
| Purgatory (0) | 2025.01.25 |
| 컨슈머 랙(LAG) (1) | 2024.12.02 |