
데이터 스트림(이벤트 스트림, 스트리밍 데이터)
데이터 스트림이란 ‘무한’히 늘어나는 데이터세트(unbounded dataset)를 추상화한 것이다.
- 시간이 흐름에 따라 새로운 레코드가 계속해서 추가되기 때문에 데이터 세트가 무한해지는것을 의미한다.
- 이벤트 스트림이라는 단순한 모델을 통해서 우리가 분석하고자 하는 모든 비즈니스 활동을 나타낼 수 있다.
‘무한’ 이라는 특성 외 이벤트 스트림 모델의 추가적인 속성들
✅ 이벤트 스트림에는 순서가 있다.
이벤트는 그 자체로 다른 이벤트 전에 혹은 후에 발생했다는 의미를 가진다.
금융 이벤트에서 입금/출금 이벤트 순서에 따라서 처리가 달라져야 한다.
계좌에 입금한 뒤 나중에 출금하는 것과 출금을 먼저하고 부채 상환을 위해 나중에 입금하는 것은 완전히 다르다.
- 후자의 경우 초과 인출 요금이 발생하지만 전자는 그렇지 않다.
- 테이블 레코드는 항상 순서가 없는 것으로 간주되며 SQL 문의 ‘order by’ 절은 관계형 모델의 일부는 아니고, 보기 편하라고 추가된 기능
✅ 데이터 레코드는 불변(immutable)하다.
이벤트는 한 번 발생한 뒤에는 절대로 고칠 수 없다. (보상 트랜잭션을 생각해보자)
취소된 금융 거래는 기존 거래가 취소되었다는 의미의 추가적인 이벤트가 스트림에 쓰여진다.
- 고객이 사갔던 상품을 반품할 경우, 과거에 팔렸다는 사실을 삭제하는 대신 반품을 추가 이벤트로 기록
DB 테이블은 레코드를 삭제하거나 변경할 수 있지만(DB 안에서 일어나는 트랜잭션) 이벤트 스트림은 모든 트랜잭션을 포함하기 때문에 이러한 작업 내역들도 기록된다.
- 레코드를 테이블에 추가한 뒤 삭제하면 해당 테이블은 더 이상 레코드를 포함하고 있지 않지만, redo log는 추가와 삭제라는 두 개의 트랜잭션을 포함하게 된다.
✅ 이벤트 스트림은 재생(replay)이 가능하다.
소켓을 통해 들어오는 TCP 패킷은 보통 재생이 불가능하지만 오래 전에 발생한 로 스트림(raw stream)을 그대로 재생할 수 있다.
- 에러를 수정하거나, 새로운 분석 방법을 시도하거나, 감사를 수행할 수 있다.
카프카는 이벤트 스트림을 캡처하고 재생할 수 있다.
스트림 처리란?
스트림 처리란 하나 이상의 이벤트 스트림을 계속해서 처리하는 것을 의미한다.
- 스트림 처리는 요청-응답이나 배치 처리와 마찬가지로 프래그래밍 패러다임 중 하나다.
✅ 요청-응답(Request-Response) 패터다임
응답 시간이 1ms 미만 ~ 몇 ms 수준으로 가장 지연이 적은 패러다임이다.
보통 애플리케이션이 요청을 보낸 뒤 처리 시스템이 응답을 보내 줄 때까지 대기하는 blocking 방식이다.
- DB 세계에서 이 패러다임은 OLTP(Online Transaction Processing
- POS(Point-Of-Sale) 시스템, 신용카드 결제 시스템, 시간 추적 시스템등에서 이 패러다임으로 동작함
✅ 배치 처리(batch processing) 패터다임
지연이 크지만, 처리량이 큰 방식으로 사전 설정된 시각에 시작된다. (스케줄러)
- 필요한 모든 입력 데이터를 읽고, 모든 출력 데이터를 쓰고, 다음 번 실행 시간까지 대기하는 식이다.
- DB 세계에서 데이터 웨어하우스나 비즈니스 인텔리전스 시스템이 이러한 부류에 속한다.
- 사용자들은 대량의 배치 단위로 적재가 완료되어야 다른 데이터를 볼 수 있다.
✅ 스트림 처리
연속적이며 논블로킹하게 작동하는 방식으로 이벤트 처리에 요청-응답 모델 방식과 배치 처리 사이의 격차를 메워준다.
- 대부분 비즈니스 프로세스는 연속적으로 발생한다.
- 비즈니스 리포트가 지속적으로 업데이트되고 최일선의 비즈니스 애플리케이션들이 계속해서 응답할 수만 있다면 수 ms 내의 응답을 기다릴 필요없이 처리할 수 있다.
의심스러운 신용카드 결제, 네트워크 사용 내역을 알린다든가, 수요와 공급에 맞춰 실시간으로 가격을 조정한다든가, 물품 배송을 추적하는 것(GPS)등이 ‘연속적이지만 논블로킹한 처리’에 딱 맞는다.
무한한 크기의 데이터세트에서 연속적으로 데이터를 읽어와서, 뭔가를 하고, 결과를 내보내는 한 우리는 스트림 처리를 수행하고 있는 것이다. (지속적으로 계속되어야 한다.)
- 특정 시간에 몇개의 데이터를 읽어서 처리하고, 결과를 내놓은 뒤 끝나는 프로세스는 스트림 처리 프로세스라고 할 수 없다. (배치 처리에 더 가깝다.)
스트림 처리 개념
1️⃣ 토폴로지 (topology)
스트림 처리 애플리케이션은 하나 이상의 처리 토폴로지를 포함한다.
하나의 처리 토폴로지는 하나 이상의 소스 스트림, 스트림 프로세서의 그래프, 하나 이상의 싱크 스트림이 서로 연결되어 있다.

- 하나 이상의 소스 스트림에서 시작된 이벤트 스트림은 연결된 스트림 프로세서들을 거쳐가면서 처리되다가 마지막에는 하나 이상의 싱크 스트림에 결과를 쓰는 것으로 끝나게 된다.
- 각각의 스트림 프로세서는 이벤트를 변환하기 위해 이벤트 스트림에 가해지는 연산 단계라고 할 수 있다.
2️⃣ 시간 (time)
시간이란 스트림 처리에서 가장 중요한 개념인 동시에 많은 경우 가장 혼란스러운 개념이다. (분산 시스템)
- 스트림 처리의 맥락에서, 대부분의 스트림 애플리케이션이 시간 윈도우(time window)에 대해 작업을 수행하는 만큼 시간에 대해 공통적인 개념을 가지는 것은 매우 중요하다.
최근 5분 사이의 주가의 이동 평균을 구하는 스트림 애플리케이션을 생각해보자
- 이동 평균이기 때문에 이전에 평균값을 알아야 한다.
- 장애로 인해서 두 시간치 데이터를 한꺼번에 처리해야할 경우 대부분의 데이터는 최근에 해당하지 않는 지난간 값으로 이미 어딘가에 저장되었을 5분 길이의 시간 윈도우에 대해서만 의미가 있다.
📌 스트림 처리 시스템의 시간 개념
✅ 이벤트 시간(event time)
이벤트가 발생하여 레코드가 생성된 시점을 말하며, 대부분의 경우 스트림 데이터를 처리할 때 가장 중요하다.
- v0.10.0 이후부터 카프카는 프로듀서 레코드를 생성할 때 기본적으로 현재 시간을 추가
이벤트가 발생하고 시간이 조금 지난 뒤에 DB 레코드를 기준으로 카프카 레코드를 생성할 경우
- 레코드에 이벤트 시간을 가리키는 필드 추가하고 나중에 두 시간을 모두 활용할 수 있게 하는 방법을 권한다.
✅ 로그 추가 시간(log append time)
이벤트가 카프카 브로커에 전달되어 저장된 시점이며, 접수 시간(ingestion time)이라고도 불린다.
- v0.10.0 이후부터 카프카가 로그 추가 시간을 저장하도록 설정되어 있거나 타임스탬프가 포함되어 있지 않은 구버전 프로듀서에서 보낸 레코드일 경우 레코드에 로그 추가 시간을 자동으로 추가한다.
- 스트림 처리에서는 이벤트가 발생한 시간이 관심사이기 때문에 보통 덜 중요하다.
실제 이벤트 시간이 기록되지 않는 경우 로그 추가 시간은 여전히 일관성 있는 시간 기준으로 사용될 수 있다.
- 레코드가 생성된 다음부터는 변하지 않는 값이다. (파이프라인 지연이 없다고 가정- 레코드 생성 이후 접수)
- 이벤트 시간에 대한 합리적인 근사값으로 볼 수 있다.
✅ 처리 시간(processing time)
스트림 처리 애플리케이션이 뭔가 연산을 수행하기 위해 이벤트를 받은 시간
- 이벤트가 발생한 뒤 몇 ms, 몇 시간, 심지어 며칠 뒤일 수도 있다.
동일한 이벤트라고 하더라도 정확히 언제 스트림 처리 애플리케이션이 이벤트를 읽었느냐에 따라서 전혀 다른 타임스탬프가 주어질 수 있다.
- 같은 애플리케이션 안에서도 스레드별로 다를 수 있다.
- 이 데이터를 활용하는 것은 신뢰성이 떨어지며 가능하면 피하는 것이 좋다.
💻 카프카 스트림즈
카프카 스트림즈는 TimestampExtractor 인터페이스를 사용해서 각각의 이벤트에 시간을 부여한다.
- 이 인터페이스의 서로 다른 구현체를 사용해서 위에서 설명한 세 가지 시간 개념 중 하나를 사용하거나 이벤트 내용에서 타임스탬프를 결정하는 등 완전히 다른 시간 개념을 사용할 수 있다.
카프카 스트림즈가 결과물을 토픽에 쓸 때, 아래 규칙에 따라서 이벤트에 타임스탬프를 부여한다.
- 결과 레코드가 입력으로 주어진 레코드에 직접적으로 대응될 경우, 결과 레코드는 입력 레코드와 동일한 타임스탬프를 사용한다.
- 결과 레코드가 집계(aggregation) 연산의 결과물일 경우, 집계에 사용된 레코드 타임스탬프의 최대 값을 결과 레코드의 타임스탬프로 사용한다.
- 결과 레코드가 두 스트림을 join한 결과물일 경우, 집계에 사용된 레코드 타임스탬프의 최대 값을 결과 레코드의 타임스탬프로 사용한다.
- 스트림과 테이블을 조인할 경우, 스트림 레코드 쪽의 타임스탬프가 사용된다.
- punctuate()와 같이 입력과 상관없이 특정한 스케줄에 따라 데이터를 생성하는 카프카 스트림즈 함수에 의해 생성된 결과 레코드의 경우, 타임스탬프 값은 스트림 처리 애플리케이션의 현재 내부 시각에 따라 결정된다.
카프카 스트림의 DSL 대신에 저수준 처리 API를 사용하고 있을 경우
- 카프카 스트림즈는 레코드의 타임스탬프를 직접적으로 다룰 수 있도록 해주는 API를 포함한다.
- 애플리케이션의 비즈니스 로직의 요구 조건에 맞는 타임스탬프 의미 구조를 직접 개발해서 사용할 수 있다.
⚠️ 시간대(timezone)에 주의하자
전체 데이터 파이프라인이 표준화된 시간대 하나만 쓰지 않으면 스트림 작업이 혼란스러운 결과를 내놓거나 의미가 없을 수 있다.
- 서로 다른 시간대의 데이터 스트림을 다뤄야 한다면, 윈도우에 작업을 수행하기 전에 이벤트 시각을 하나의 시간대로 변환하자.
- 레코드에 시간대 정보를 저장해 넣는 경우도 많다.
3️⃣ 상태(state)
스트림 처리는 다수의 이벤트가 포함되는 작업을 잘해야한다.
- 이벤트 종류별로 집계, 이동 평균, 2개의 스트림을 조인해서 확장된 정보를 보유하는 스트림 생성등
- 각각의 이벤트를 따로따로 처리해야만 한다면 스트림 프로세싱은 매우 간단하다.
예를 들어 지금 한 시간 동안 발생한 타입별 이벤트 수나 조인, 합계 및 평균을 계산해야 하는 모든 이벤트 등 더 많은 정보를 추적 관리해야 한다.
- 이러한 정보를 상태라 부른다.
- 스트림 이벤트의 개수를 저장하는 간단한 해시 테이블처럼, 스트림 처리 애플리케이션의 로컬 변수에 상태를 저장하면 된다고 생각할 수 있다.
- 스트림 처리 애플리케이션이 정지하거나 크래시 날 경우 상태가 유실되고 결과가 달라지기 때문에 스트림 처리에서 상태를 관리하는 방법으로서는 신뢰성이 떨어진다.
- 최신 상태를 보존하면서 애플리케이션을 재시작할 때 상태가 복구되도록 신경써야 한다.
📌 스트림 처리에서 상태 유형
✅ 로컬 혹은 내부 상태
스트림 처리 애플리케이션의 특정 인스턴스에서만 사용할 수 있는 상태
- 대개 애플리케이션에 포함되어 구동되는 내장형 인메모리 DB를 사용해서 유지 관리된다.
- 엄청 빠르지만 사용 가능한 메모리 크기의 제한을 받는다.
스트림 처리의 많은 디자인 패턴들은 데이터를 분할해서 한정된 크기의 로컬 상태를 사용해서 처리 가능한 서브스트림(substream)으로 만드는 데 초점을 둔다. (찾아보기)
✅ 외부 상태
외부 데이터 저장소에서 유지되는 상태는 많은 경우 카산드라와 같은 NoSQL 시스템을 사용해서 저장된다.
- 사실상 크기에 제한은 없으며, 여러 애플리케이션 인스턴스, 다른 애플리케이션에서도 접근이 가능하다.
- 다른 시스템을 추가하는 데 따른 지연 증가, 복잡도 증가, 가용성 문제가 있다. (애플리케이션 입장에서는 외부 시스템이 사용 불가능할 때 대응할 방법이 필요하다.)
많은 스트림 처리 애플리케이션은 외부 저장소 사용을 피한다.
- 내용물을 로컬 상태에 캐시함으로써 외부 저장소와 가능한 통신하지 않게 함으로써 지연 부담을 최소화 할 수 있지만, 애플리케이션 내부 상태와 외부 상태를 일관적으로 유지해야 한다.
4️⃣ 스트림-테이블 이원성(Stream-Table Duality)
DB 테이블은 과거의 변경 내역을 저장하도록 특별히 설계되지 않았다면 과거 데이터를 찾을 수 없지만 스트림은 변경 내역을 저장한다.
- 스트림은 변경을 유발하는 이벤트의 연속이지만, 테이블은 여러 상태 변경의 결과물인 현재 상태를 저장한다.
테이블을 스트림으로 변경하기 위해서는 테이블을 수정한 변경 내역을 잡아내야 한다.
- 모든 추가, 변경, 삭제 이벤트를 가져와서 스트림에 저장하면 된다.
- 많은 DB들은 변경점들을 잡아내기 위해 CDC 솔루션을 제공하며, 스트림 처리에서 활용할 수 있도록 카프카로 전달해 줄 수 있는 커넥터가 많이 있다.
스트림을 테이블로 변경하기 위해서는 스트림에 포함된 모든 변경 사항을 테이블에 적용해야 한다.

- 메모리든, 내부/외부 상태 저장소든 테이블을 생성한 뒤 스트림에 포함된 이벤트를 처음부터 끝까지 모두 읽어서 상태를 변경한다.

- 모든 상태 변경이 끝나면 특정 시점의 상태를 나타내는 테이블을 얻을 수 있다. (스트림 구체화)
5️⃣ 시간 윈도우(Time Windows)
대부분의 스트림 작업은 시간을 윈도우라 불리는 구간 단위로 잘라서 처리한다.
- 이동 평균 계산, 이번 주 가장 많이 팔린 상품 계산, 시스템의 99분위 부하 찾기
두 스트림을 조인하는 작업 역시 윈도우 작업이다.
- 동일한 시간 간격 안에 발생한 이벤트들끼리 조인할 수 있다.
📌 작업을 수행할 윈도우 고민하기
✅ 윈도우 크기
윈도우 크기가 커질수록(5분, 5일, 5달…) 평균값은 완만해지겠지만 랙(lag) 역시 커진다.
- 주가가 오를 경우, 윈도우가 작은 경우보다 큰 경우가 더 알아차리기 어렵다.
카프카 스트림은 윈도우의 크기가 비활동(inactivity) 기간의 길이에 따라 결정되는 세션 윈도우 역시 지원한다.
- 개발자가 세션 간견(session gap)을 정의하면, 세션 간격보다 작은 시간 간격을 두고 연속적으로 도착한 이벤트들은 하나의 세션에 속하게 된다.
- 세션 갭 이상으로 이벤트가 도착하지 않으면 새로운 세션이 생성되어 이후 도착하는(그 다음 세션 이전) 이벤트들을 담게 된다.
✅ 시간 윈도우의 진행 간격
- 5분 단위 평균은 매분, 매초, 혹은 새로운 이벤트가 도착할 때마다 업데이트될 수 있다.
스트림즈 DSL - window processing
스트림즈 데이터를 분석할 때 가장 많이 활용하는 프로세싱 중 하나는 윈도우 연산이다.
- 모든 프로세싱은 메시지 키를 기준으로 취합하기 때문에, 해당 토픽에 동일한 파티션에는 동일한 메시지 키가 있는 레코드가 존재해야만 정확한 취합이 가능하다.
- 커스텀 파티셔너를 사용하여 동일 메시지 키가 동일한 파티션에 저장되는 것을 보장하지 못하거나 메시지 키를 넣지 않으면 관련 연산이 불가능하다.
호핑 윈도우(hopping window)
- 윈도우의 크기와 윈도우 사이의 고정된 시간 간격이 같은 윈도우
일정 시간 간격으로 겹치는 윈도우가 존재하는 윈도우 연산을 처리하는 경우 사용한다.

- 호핑 윈도우는 윈도우 사이즈와 윈도우 간격 2가지 변수를 가진다.
- 윈도우 사이즈는 연산을 수행할 최대 윈도우 사이즈를 뜻하고 윈도우 간격은 서로 다른 윈도우 간 간격을 뜻한다.
- 텀블링 윈도우와 다르게 동일한 키의 데이터는 서로 다른 윈도우에서 여러번 연산될 수 있다.
텀블링 윈도우(tumbling window)
- 진행 간격(advance interval)과 윈도우 크기가 같은 경우
서로 겹치지 않은 윈도우를 특정 간격으로 지속적으로 처리할 때 사용한다.
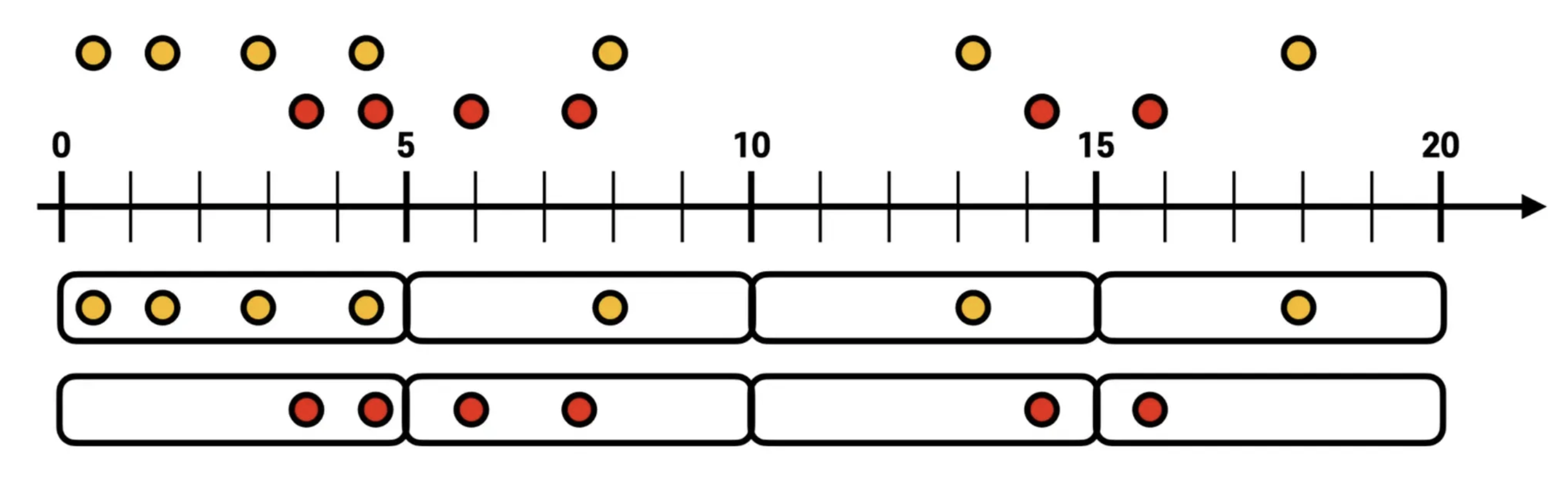
- 윈도우 최대 사이즈에 도달하면 해당 시점에 데이터를 취합하여 결과를 도출한다.
- 단위 시간당 데이터가 필요할 경우 사용할 수 있다.
(5분간 접속한 고객의 수를 측정하여 방문자 추이를 실시간으로 취합하는 경우) - 윈도우 간격 외에 추가적인 간격(Grace)을 두어 늦게 도착하는 데이터도 처리할 수 있다. (ofSizeAndGraze)
💻 예제 코드
- 카프카 스트림즈에서 텀블링 윈도우를 사용하기 위해서는 groupByKey와 windowedBy를 사용해야 한다.
- windowedBy의 파라미터는 텀블링 윈도우의 사이즈를 뜻한다.
- 텀블링 연산으로 출력된 데이터는 KTable로 커밋 interval 마다 출력된다.
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> stream = builder.stream(TEST_LOG);
// 해당 토픽에 대해서 키를 기준으로 그룹을 하지만 타임 윈도우를 5초마다 하고 카운트를 지정하게 되면
// 5초 마다 TEST_LOG에 들어오는 데이터가 5초안에 몇개나 들어왔는지 지속적으로 카운트해서 Ktable로 조회가 된다.
// KTable이니까 실시간으로 업데이트
KTable<Windowed<String>, Long> countTable = stream.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofSeconds(5)))
.count();
// 특정 데이터 키가 5초마다 몇개가 들어왔는지 알 수 있다.
countTable.toStream().foreach(((key, value) -> {
log.info(key.key() + " is [" + key.window().startTime() + "~" + key.window().endTime() + "] count : " + value);
}));
슬라이딩 윈도우
호핑 윈도우와 유사하지만 데이터의 정확한 시간을 바탕으로 윈도우 사이즈에 포함되는 데이터를 모두 연산에 포함시키는 특징이 있다.

- 여기서 말하는 시간은 시스템 시간, 각각의 레코드 시간으로 나눌 수 있다.
- 시스템 시간은 서버가 돌아가는 시간을 뜻하는데 각각의 레코드에 포함된 timeStamp의 정확한 시간을 토대로 슬라이딩 윈도우를 사용하면 특정 데이터들은 몇 분 간격안에 무조건 포함되어 있음을 파악할 수 있다.
세션 윈도우
동일 메시지 키의 데이터를 한 세션에 묶어 연산할 때 사용한다.
- 세션의 최대 만료시간에 따라 윈도우 사이즈가 달라진다.

- 세션 만료 시간이 지나게 되면 세션 윈도우가 종료되고 해당 윈도우의 모든 데이터를 취합하여 연산한다.
- 즉, 세션 만료 시간에 따라서 세션 윈도우의 사이즈는 가변적이다.
- 최대 만료시간이 지나게 되면 각각의 다른 윈도우 세션으로 분리 되어서 연산이 처리된다는 특징이 있다.
스트림즈DSL - 윈도우 연산시 주의해야할 사항 ⚠️
- 카프카에서는 커밋 단위로 윈도우의 연산이 출력된다.

- 0~5초 사이의 데이터를 윈도우 간격을 재고 있지만 중간 3초때 커밋을 하기 때문에 이 때 출력데이터를 3초까지 취합한 데이터(A,2)가 나오게 된다.
커밋 시점마다 윈도우의 연산 데이터를 출력하기 때문에 동일 윈도우 사이즈(시간)의 데이터는 2개 이상 출력될 수 있다.
- 0~5초, 6~10초 사이의 데이터를 윈도우 간격으로 재고 있을 때 6초와 9초에서 동일한 6~10초 데이터가 출력될 수 있다.
🤔 해결 방법
최종적으로 각 윈도우에 맞는 데이터를 출력하고 싶다면 Windowed를 기준으로 동일 윈도우 시간 데이터는 겹쳐쓰기(upsert)하는 방식으로 처리하는 것이 좋다.

- 0~5초라는 인터벌과 통일한 키가 있는 경우 가장 나중에 들어온 데이터가 유효한 값이라는 것을 알 수 있다.
최초에 0~5초 A데이터가 2개가 취합된 데이터가 처음 저장되고, 추후에 6초에 출력된 3개 취합된 데이터가 최종 저장되면서 결과적으로 A가 0~5초에 3개 count 된 것을 확인할 수 있다.
6️⃣ 처리 보장
스트림 처리 애플리케이션에 있어서 핵심적인 요구 조건 중 하나는 장애가 발생했을 경우에도 각각의 레코드를 한 번만 처리할 수 있는 능력이다.
- ‘정확히 한번’이 보장되지 못하면 스트림 처리는 정확한 결과가 요구되는 상황에서 사용될 수 없다.
- 카프카의 트랜잭션 기능을 사용해서 스트림 처리 애플리케이션에 ‘정확히 한 번’ 보장을 지원한다.
스트림 처리 디자인 패턴
컨슈머, 처리 로직, 프로듀서를 엮어 놓은 가장 단순한 형태부터 스파크 스트리밍과 같은 복잡한 형태까지 모든 스트림 처리 시스템은 서로 다르다.
단일 이벤트 처리
가장 단순한 스트림 처리 패턴은 맵/필터 패턴으로 알려져 있는데 각각의 이벤트를 개별적으로 처리하는 것이다.
- 불필요한 이벤트를 스트림에서 걸러 내거나 각 이벤트를 변환하기 위해 사용되는 경우가 많다.
- map/reduce 패턴에서 유래했다. 맵에서는 이벤트를 변환하고, 리듀스 단계에서는 집계한다.
이 패턴에서 스트림 처리 애플리케이션은 스트림의 이벤트를 읽어와서 각각의 이벤트를 수정한 뒤, 수정된 이벤트를 다른 스트림에 쓴다.
- 스트림으로 부터 로그 메시지를 읽어와서 ERROR 이벤트를 우선순위가 높은 스트림에, 나머지를 우선순위가 낮은 스트림에 쓰는 애플리케이션
- 스트림으로 부터 JSON 이벤트를 읽어 와서 수정한 뒤 AVRO 형식으로 쓰는 애플리케이션

각각의 이벤트가 독립적으로 처리될 수 있기 때문에, 애플리케이션 안에 상태를 유지할 필요가 없다.
- 상태를 복구할 필요도 없기 때문에 장애 복구나 부하 분산(load balancing)이 매우 쉽다.
- 다른 애플리케이션 인스턴스가 이벤트를 넘겨받아 처리하게 하면 된다.
이 패턴은 간단한 프로듀서와 컨슈머를 사용해서 쉽게 처리가 가능하다.
로컬 상태와 스트림 처리
대부분의 스트림 처리 애플리케이션은 윈도우 집계와 같이 정보의 집계에 초점을 맞춰어 스트림의 상태(state)를 유지할 필요가 있다.
- 각각의 작업은 그룹별 집계일 수 있으며 공유 상태(shared state)가 아닌 로컬 상태(local state)를 사용해서 수행할 수 있다.
카프카 파티셔너를 사용해서 동일한 모든 이벤트가 동일한 파티션에 쓰여지도록 하고, 각각의 애플리케이션 인스턴스는 자신에게 할당된 파티션에 저장된 모든 이벤트를 읽어온다. (카프카 컨슈머 단위에서 보장)
- 애플리케이션의 각 인스턴스는 자신에게 할당된 파티션에 쓰여진 이벤트 상태를 유지할 수 있다. (전체 주식 종목의 부분집합에 대한 상태등)

로컬 상태를 보유하게 될 때 스트림 처리 애플리케이션이 고려해야 할 사항
✅ 메모리 사용
로컬 상태는 애플리케이션 인스턴스가 사용 가능한 메모리 안에 들어갈 수 있는 게 이상적이다.
- 어떠한 로컬 저장소로 디스크에 내용물을 저장(spilling)하는 기능을 지원하지만, 성능에 큰 영향을 미친다.
✅ 영속성
애플리케이션 인스턴스가 종료되었을 때 상태가 유실되면 않고, 인스턴스가 재실행 되거나 다른 인스턴스에 의해서 대체되었을 때 복구될 수 있음을 확신할 수 있어야 한다.
카프카 스트림즈는 내장된 RocksDB를 사용함으로써 로컬 상태를 인메모리 방식으로 저장함과 동시에 재시작 시 빠르게 복구가 가능하도록 디스크에 데이터를 영속적으로 저장한다.
- 로컬 상태에 대한 모든 변경 사항은 카프카 토픽에도 보내진다.
- 카프카 토픽으로부터 이벤트를 읽어옴으로써 쉽게 복구될 수 있다.
끝없이 자라나는 상태들을 방지하고 상태 복구를 언제고 실행 가능하게 하기 위해 로그 압착을 사용한다.
✅ 리밸런싱
파티션이 서로 다른 컨슈머에게 재할당되어, 파티션을 상실한 애플리케이션 인스턴스는 마지막 상태를 저장함으로써 해당 파티션을 할당받은 인스턴스가 재할당 이전 상태를 복구시킬 수 있도록 해야 한다.
📌 지원되는 로컬 상태 관리 기능의 수준은 스트림 처리 프레임워크 별로 다르다.
- 사용중인 프레임워크가 로컬 상태를 보장하는지 여부를 확인할 필요가 있다.
다단계 처리/리파티셔닝
그룹별 집계가 필요할 때는 로컬 상태를 사용하는개 좋지만, 사용 가능한 모든 정보를 사용해서 결과를 내야 될 수 있다.
(매일 개장부터 폐장까지 가장 많이 오른 주식 상위 10개를 계산한다고 가정)
상위 10개 주식 전체가 서로 다른 인스턴스에 할당된 파티션에 분산되어 있을 수 있다.
- 각 주식별로 하루 동안의 상승/하락을 산출한다. (각 인스턴스에서 로컬 상태를 통해서 처리 가능)
이후 하나의 파티션만 가진 새로운 토픽에 결과를 쓴다.
- 이 토픽은 전체 거래 내역을 포함하는 토픽에 비해 크기도 트래픽도 훨씬 작기 때문에, 단일 인스턴스만 가지는 애플리케이션만으로도 충분히 처리할 수 있다.

대부분의 스트림 처리 프레임워크는 어느 애플리케이션 인스턴스(혹은 worker)가 어느 단계를 수행할지 등의 세부적인 사항들을 프레임워크가 알아서 해주도록 함으로써 모든 단계를 하나의 애플리케이션에 담을 수 있다.
외부 검색을 사용하는 처리: 스트림-테이블 조인
스트림 처리를 할 때 때로는 외부 데이터를 스트림과 조인해야 한다. (데이터 확장등)
단순하지만 상당한 지연을 발생시키는 구조 (현실성 X)
클릭 이벤트가 발생해 스트림으로 들어올 때마다 DB에서 사용자를 조회한 뒤, 클릭 이벤트 데이터와 합쳐서 새로운 이벤트를 다른 토픽에 쓴다.

- 외부 데이터 저장소를 포함하는 스트림 처리
- 스트림 처리 시스템은 초당 10만~50만 개의 이벤트를 처리할 수 있지만 DB는 초당 1만 개 가량의 이벤트를 처리할 수 있는게 보통이다. (가용성 보장을 위해 수반되는 복잡성 역시 걸림돌이다.)
🤔 성능과 가용성을 두 가지를 잡기 위해서는?
스트림 처리 애플리케이션 안에 DB에 저장된 데이터를 캐시할 필요가 있다.
- 캐시를 관리하는 게 만만치 않을 수 있다.
DB에 가해지는 변경 이벤트를 너무 자주 가져오게 되면 DB를 건드리는 꼴이 되므로 캐시가 도움이 되지 않고, 새 이벤트를 가져오는 데 시간이 너무 오래 걸린다면 이미 만료된 정보를 가지고서 스트림 처리를 하는 꼴이 된다.
- DB 테이블에 가해지는 모든 변경점을 이벤트 스트림에 담을 수 있다면, 스트림 처리 작업이 이 스트림을 받아와서 캐시를 업데이트 하는 데 사용하도록 할 수 있다.
DB의 변경 내역을 이벤트 스트림으로 받아오는 것을 CDC(change data capture)라고 한다.
- 카프카 커넥터는 CDC를 수행하여 DB 테이블을 변경 이벤트 스트림으로 변환할 수 있는 커넥터가 여럿 있다.
- 이것을 사용해서 테이블의 복사본을 따로 유지할 수 있는 동시에 DB 변경 이벤트가 발생할 때마다 알림을 받아서 테이블 복사본을 적절히 업데이트할 수 있다.

클릭 이벤트를 받을 때마다 로컬 상태에서 user_id를 찾아서 이벤트를 확장할 수 있다.
- 로컬 상태를 사용하기 때문에 훨씬 더 확장하기 용이하며, DB와 이를 사용하는 다른 애플리케이션에 영향을 주지 않는다.
- 스트림 중 하나가 로컬에 캐시된 테이블에 대한 변경 사항을 나타내는 것을 스트림 테이블 조인이라고 부른다.
테이블-테이블 조인
두 개의 테이블을 조인하는 것은 언제나 윈도우 처리되지 않는 연산이며, 작업이 실행되는 시점에서의 양 테이블의 현재 상태를 조인한다.
- 카프카 스트림에서는 동일한 방식으로 파티션된 동일한 키를 가지는 두 개의 테이블에 대해 동등 조인(equi-join)을 수행할 수 있어서, 조인 연산이 많은 수의 애플리케이션 인스턴스와 장비에 효율적으로 분산될 수 있게 한다.
- 카프카 스틀미즈는 한 스트림 혹은 테이블의 키와 다른 스트림 혹은 테이블의 임의의 필드를 조인할 수 있도록 외래 키(FK)를 지원한다.
Real-Time Data Enrichment with Kafka Streams: Introducing Foreign-Key Joins
Foreign-key joins allow for data enrichment from multiple sources using joins, moving the incremental materialized view maintenance workload outside of single-node databases into a scalable distributed system by making use of streaming data.
www.confluent.io
Crossing the Streams: the New Streaming Foreign-Key Join Feature in Kafka Streams - Confluent
"Kafka Streams, Apache Kafka’s stream processing library, allows developers to build sophisticated stateful stream processing applications which you can deploy in an environment of your choice.
www.confluent.io
스트리밍 조인
😎 두 개의 이벤트 스트림(무한)을 조인해야 할 경우
테이블에서는 현재 상태만 관심사이기 때문에 스트림을 사용해서 테이블을 나타낼 때 우리는 스트림에 포함된 대부분의 과거 이벤트는 무시할 수 있다.
하지만 두 개의 스트림을 조인할 경우 한쪽 스트림에 포함된 이벤트를 같은 키값과 함께 같은 시간 윈도우에 발생한 다른쪽 스트림 이벤트와 맞춰야 한다.
- 과거와 현재의 이벤트 전체를 조인하게 된다. (스트리밍 조인을 윈도우 조인이라고 부르는 이유)
📌 사용자들이 입력한 검색 쿼리를 담은 스트림과 검색 결과 클릭 내역을 포함한, 클릭 내역을 담은 스트림을 조인
- 검색 기간을 기준으로 하되 특정한 시간 윈도우 범위 안에 있는 검색 결과하고만 맞춰야 한다.
- 쿼리가 우림의 검색 엔진에 들어온 지 몇 초 뒤에 결과가 클릭될 것이라고 가정할 수 있으며, 각 스트림에 대해서 몇 초 정도의 길이를 가지는 윈도우를 유지하면서 각 윈도우에 속한 이벤트끼리 맞춰줘야 한다.

- 두 개의 이벤트 스트림을 조인하기, 이 조인에는 항상 이동하는 시간 윈도우가 수반된다.
카프카 스트림즈는 조인할 두 스트림(search와 clicks)이 똑같이 조인 키에 대해 파티셔닝되어 있을 경우 동등 조인을 지원한다.
- 특정 사용자(조인 키)의 이벤트들은 search와 clicks 토픽 각각에 특정 파티션에 저장되었을 때 카프카 스트림즈는 두 토픽의 특정 파티션에 대한 작업을 같은 태스크(특정 사용자의 모든 연관된 이벤트)에 할당한다.
- 카프카 스트림즈는 두 토픽에 대한 조인 윈도우를 내장된 RocksDB 상태 저장소에 유지함으로써 조인을 수행한다.
비순차 이벤트
잘못된 시간에 스트림에 도착한 이벤트(비순차 이벤트)를 처리하는 것은 어렵지만 자주 발생할 수 있다.
- 예를 들어, 몇 시간 동안 WiFi 신호가 끊긴 모바일 장치가 재접속할 때

스트림 애플리케이션은 이러한 상황을 처리할 수 있어야 하며, 애플리케이션은 아래 같은 일들을 해야 한다.
- 이벤트가 순서를 벗어났음을 알아차릴 수 있어야 한다. (애플리케이션이 이벤트 시간을 확인해서 현재 시각보다 더 이전인지를 확인할 수 있어야 한다.)
- 비순차 이벤트의 순서를 복구할 수 있는 시간 영역을 정의한다. (3시간 정도면 복구가 가능하지만, 3주 이상 오래된 것은 포기하는 식)
- 순서를 복구하기 위해 이벤트를 묶을 수 있어야 한다. (스트리밍 애플리케이션과 배치 작업의 주요한 차이점)
- 배치의 경우 작업이 끝난 후 몇 개의 이벤트가 추가로 도착했다면 보통 어제 작업을 다시 돌려서 이벤트를 변경하지만, 스트림 처리에서는 이런 개념이 없다. (계속해서 돌아가는 동일한 프로세스가 주어진 시점 기준으로 오래된 이벤트와 새로운 이벤트를 모두 처리)
- 결과를 변경할 수 있어야 한다. (스트림 처리 결과가 DB에 쓰여질 경우, 결과를 변경하는 데 put 혹은 delete 정도면 충분하지만, 스트림 애플리케이션이 결과를 이메일로 전송할 경우 변경이 곤란할 수 있다)
구글의 데이터플로(Dataflow)나 카프카 스트림과 같은 스트림 처리 프레임워크는 처리 시간과 독립적인 이벤트 시간의 개념을 자체적으로 지원한다.
- 현재 처리 시간 이전 혹은 이후의 이벤트 시간을 가지는 이벤트를 다룰 수 있는 기능도 가지고 있다.
- 로컬 상태에 다수의 집계 윈도우를 변경 가능한 형태로 유지해주고, 개발자가 이 윈도우를 얼마나 오랫동안 유지할지를 설정할 수 있게 해주는 식이다. (오랫동안 변경 가능한 상태로 유지하면 메모리가 더 많이 필요)
카프카 스트림즈 API는 언제나 집계 결과를 결과 토픽에 쓰며, 이 토픽은 대체로 로그 압착이 설정되어 있다.
- 각 key 값에 대한 마지막 value값만 유지된다.
- 집계 윈도우의 결과가 늦게 도착한 이벤트로 인하여 변경되어야 하는 경우, 카프카 스트림즈는 단순히 해당 집계 윈도우의 새로운 결과값을 씀으로써 기존 결과값을 대체한다.
재처리하기 (이벤트를 재처리하는 패턴에 두 가지 변형)
1️⃣ 구버전에서 사용하던 바로 그 이벤트 스트림을 새로 개선된 버전의 스트림 처리 애플리케이션에서 읽어와서 산출된 새로운 결과 스트림을 쓴다.
- 단, 기존 구버전의 결과를 교체하는 것이 아니라 한동안 두 버전의 결과를 비교한 뒤 어느 시점에 구버전 대신 신버전의 결과를 사용하도록 한다.
- 카프카가 확장 가능한 데이터 저장소에 이벤트 스트림을 오랫동안 온전히 저장하기 때문에 간단하다.
하나의 스트림 처리 애플리케이션의 두 버전이 동시에 두 개의 결과 스트림을 쓰기 위해 지켜야 하는 조건
- 신버전 애플리케이션을 새 컨슈머 그룹으로 실행시킨다.
- 신버전 애플리케이션이 입력 토픽의 첫 번째 오프셋부터 처리를 시작하도록 설정해서 입력 스트림의 모든 이벤트에 대한 복사본을 가질 수 있도록 한다.
- 신버전 애플리케이션이 처리를 계속하도록 하고, 신버전 처리 작업이 따라잡았을 때 클라이언트 애플리케이션을 새로운 결과 스트림으로 전환한다.
2️⃣ 기존의 스트림 처리 애플리케이션에 버그가 많아서 버그를 고친 뒤 이벤트 스트림을 재처리해서 결과를 다시 산출하고자 할 때
- 이미 존재하는 애플리케이션을 초기화해서 입력 스트림의 맨 처음부터 다시 처리하도록 되돌린다. (두 애플리케이션 버전에서 나온 결과물이 뒤섞이면 안되기 때문)
- 로컬 상태를 초기화하고, 기존 출력 스트림 내용물 역시 지워야 할 수 있다.
- 카프카 스트림즈가 스트림 처리 애플리케이션의 상태를 초기화하기 위한 툴을 제공한다.
같은 애플리케이션을 두 개 돌려서 결과 스트림도 두 개가 나올 정도로 용량이 충분하다면 1️⃣을 권장한다.
- 안전하며 2개 이상의 버전을 왔다 갔다 할 수도 있고 버전 간의 결과물을 비교할 수도 있으며, 정리(cleanup)과정에서 중요한 데이터가 유실되거나 에러가 발생할 위험도 없다.
인터랙티브 쿼리(interactive query)
스트림 처리 애플리케이션은 상태를 보유하며, 이 상태는 애플리케이션의 여러 인스턴스 사이에 분산될 수 있다.
- 결과 토픽을 읽어서 처리 결과를 받을 수 있지만, 상태 저장소 그 자체에서 바로 결과를 읽어올 필요가 있을 수 있다. (처리 결과가 테이블 형태인 경우 흔하다. ex) 가장 많이 팔린 도서 10종)
- 결과 스트림은 곧 테이블에 대한 업데이트 스트림이기 때문에 이 경우 스트림 처리 애플리케이션의 상태에서 테이블을 바로 읽어오는 것이 훨씬 더 빠르고 쉽다.
카프카 스트림즈는 스트림 처리 애플리케이션의 상태를 쿼리하기 위한 유연한 API를 포함한다.
Kafka Streams Interactive Queries for Confluent Platform | Confluent Documentation
To query remote states for the entire app, you must expose the application’s full state to other applications, including applications that are running on different machines. For example, you have a Kafka Streams application that processes user events in
docs.confluent.io
카프카 스트림즈 아키텍처 개요
토플로지 생성하기
모든 스트림즈 애플리케이션은 하나의 토플로지를 구현하고 실행한다.
- 토폴로지는 다른 스트림 처리 프레임워크에서는 DAG(directed acyclic graph) 혹은 유향 비순환 그래프라고 불린다.
- 모든 이벤트가 입력에서 출력으로 이동하는 동안 수행되는 작업과 변환 처리의 집합이라고 할 수 있다.

- 각각의 프로세서는 필터, 맵, 집계 연산과 같은 데이터에 대한 처리 작업을 구현한다. (타원 노드)
- 토픽으로부터 데이터를 읽어와서 넘겨주는 source processor도 있으며, 앞 프로세서로부터 데이터를 넘겨 받아서 토픽에 쓰는 sink processor도 있다.
- 토폴로지는 항상 하나 이상의 source processor로 시작해서 한 개 이상의 sink processor로 끝난다.
토폴로지 최적화하기
기본적으로, 카프카 스트림즈는 DSL API를 사용해서 개발된 애플리케이션의 각 DSL 메서드를 독립적으로 저수준 API로 변환하여 실행한다.
- 각각의 DSL 메서드를 독립적으로 변환하기 떄문에 결과 토폴로지는 전체적으로 최적화되지 않은 상태일 수 있다.
카프카 스트림즈 애플리케이션의 실행 3단계
- KStream, KTable 객체를 생성하고 여기에 필터, 조인과 같은 DSL 작업을 수행함으로써 논리적 토폴로지를 정의한다.
- StreamsBuilder.build() 메서드가 논리적 토폴로지로부터 물리적 토폴로지를 생성해낸다.
- KafkaStreams.start() 토폴로지를 실행시켜 데이터를 읽고, 처리하고, 쓰게 된다.
📌 논리적 토폴로지에서 물리적 토폴로지가 생성되는 두 번째 단계가 최적화가 적용되는 곳이다.
아파치 카프카는 몇 개의 최적화 방식을 포함하고 있다.(대부분 가능한 한 토픽을 재활용하도록 하는 것들)
- StreamsConfig.TOPOLOGY_OPTIMIZATION 설정값을 StreamsConfig.OPTIMIZE로 잡아준 뒤 build(props)를 호출함으로써 활성화시킬 수 있다.
- 이 설정 없이 build()를 호출할 경우 최적화가 적용되지 않는다.
- 최적화된 것과 안된 것을 애플리케이션을 테스트하면서 실행 시간과 카프카에 쓰여지는 데이터의 양을 비교해보는 것이 좋다. (다양한 상황에서 동일한지 등)
토폴로지 테스트하기
카프카 스트림즈 애플리케이션의 주된 테스트 툴은 TopologyTestDriver로 v2.4부터는 사용이 더 쉬워졌다.
- 이 클래스를 사용해서 개발된 테스트는 일반적인 단위 테스트와 비슷하게 작동한다.
- 입력 데이터를 정의하고, 목업 입력 토픽에 데이터를 쓰고, 테스트 드라이버를 써서 토폴로지를 실행시키고, 목업 출력 토픽에서 결과를 읽은 뒤 예상하는 결과와 비교 검증하는 것이다.
하지만 이 클래스는 카프카 스트림즈의 캐시 기능을 시뮬레이션해주지는 않으므로 찾을 수 없는 에러도 많다.
- 즉, 캐시는 TopologyTestDriver가 시뮬레이션하는 상태 저장소 관련 기능과 완전히 상관없다.
단위 테스트는 통합 테스트로 보강되는 것이 보통인데, 카프카 스트림즈의 경우 EmbeddedKafkaCluster와 Testcontainers의 두 통합 테스트 프레임워크가 자주 쓰인다.
- 전자는 테스트를 수행하는 JVM 상에 카프카 브로커를 하나 띄워주는 방식
- 후자는 도커 컨테이너를 사용해서 카프카 브로커와 기타 테스트에 필요한 다른 요소들을 띄워주는 방식
- 도커를 사용해서 카프카와 그 의존성, 사용되는 리소스를 테스트 애플리케이션으로부터 완전히 격리시키기 때문에 후자가 더 권장된다.
Testing Kafka Streams - A Deep Dive
Learn how to test Kafka Streams with TopologyTestDriver, EmbeddedKafka, or TestContainers, their shortcomings, and challenges for each test.
www.confluent.io
토폴로지 규모 확장하기
카프카 스트림즈는 하나의 애플리케이션 인스턴스 안에 다수의 스레드가 실행될 수 있게 함으로써 규모 확장과 서로 다른 애플리케이션 인스턴스 간에 부하 분산이 이루어지도록 한다.
- 하나의 장비 다수의 스레드, 여러대 장비에서 실행 시킬 수 있는데 어느 경우건 애플리케이션의 모든 할성화된 스레드들은 데이터 처리에 수반되는 작업을 균등하게 수행한다.
카프카 스트림즈 엔진은 토폴로지의 실행을 다수의 태스크로 분할함으로써 병렬 처리한다.
- 스트림즈 엔진은 애플리케이션이 처리하는 토픽의 파티션 수에 따라 태스크 수를 결정한다.
각 태스크는 자신이 담당하는 파티션들을 구독해서 이벤트를 읽어온다.
- 이벤트를 읽어 올 때마다 태스크는 이 파티션에 적용될 모든 처리 단계를 실행시킨 후 결과를 싱크에 쓴다.
- 이러한 태스크들은 서로 완전히 독립적으로 실행될 수 있기 때문에 카프카 스트림즈에서 병렬 처리의 기본 단위가 된다.

처리하는 토픽의 파티션 수 만큼의 태스크를 생성하는 것이 스트리밍 애플리케이션이 규모를 확장하는 방식이다.
- 다수의 애플리케이션 인스턴스가 다수의 서버에서 실행될 경우, 각 서버의 스레드별로 서로 다른 태스크가 실행될 것이다.
스레드 수를 늘리거나, 인스턴스를 더 띄우면(scale out) 카프카가 자동으로 작업을 코디네이션할 것이다.
- 카프카가 각각의 태스크에 파티션을 나눠서 할당해주면 각각의 태스크는 자신이 할당받은 파티션에서 독립적으로 이벤트를 받아와서 처리하고 토폴리지에 정의된 집계 연산에 관련된 로컬 상태를 유지한다.

📌 태스크 간 의존성이 생길 수 있는 경우
1️⃣ 다수의 파티션에서 입력을 가져와서 처리해야 할 때, 각 파티션의 파티션으로부터 데이터를 읽어와서 스트림 혹은 테이블이 조인할 때 태스크 사이에 의존 관계가 생길 수 있다.
- 카프카 스트림즈는 각각의 조인 작업에 필요한 모든 파티션들을 하나의 태스크에 할당한다.
- 해당 태스크가 필요한 파티션 전부로부터 데이터를 읽어온 뒤 독립적으로 조인을 수행할 수 있도록 함으로써 이러한 상황을 해결한다.
따라서 카프카 스트림즈가 조인 작업에 사용될 모든 토픽에 대해서 동일한 조인 키로 파티션된 동일한 수의 파티션을 가져야 한다.
2️⃣ 애플리케이션이 리파티셔닝을 해야할 때
사용자의 ID로 조인한 뒤 사용자의 지역을 기준으로 처리한다면 리파티션 한 뒤 새 파티션을 가지고 집계 연산을 실행시켜야 한다.
⚠️ 웬만하면 리파티셔닝(Repartitioning)을 남용하지 말자
키 변경 연산이 수행되면 변경된 키에 따라서 토픽 파티션을 이동시키는 작업인 리파티셔닝(Repartitioning)이 발생하게 된다.
- 대규모 데이터 이동으로 네트워크/디스크/IO 부하가 발생할 수 있다.
- 따라서 가급적, 키 변경 연산(map, transform, flatMap, groupBy)보다는 mapValues, transformValues, flatMapValues, groupByKey의 사용을 권장한다.
다른 스트림 처리 프레임워크와는 달리, 카프카 스트림즈는 리파티션이 호출되면 새로운 키와 파티션을 가지고 새로운 토픽에 이벤트를 쓰기 때문이다.
- 그리고 그 다음에 오는 태스크들이 새 토픽에서 이벤트를 읽어와서 처리를 계속하기 때문에, 전체 토폴로지를 2개의 서브 토폴로지로 분할한다.
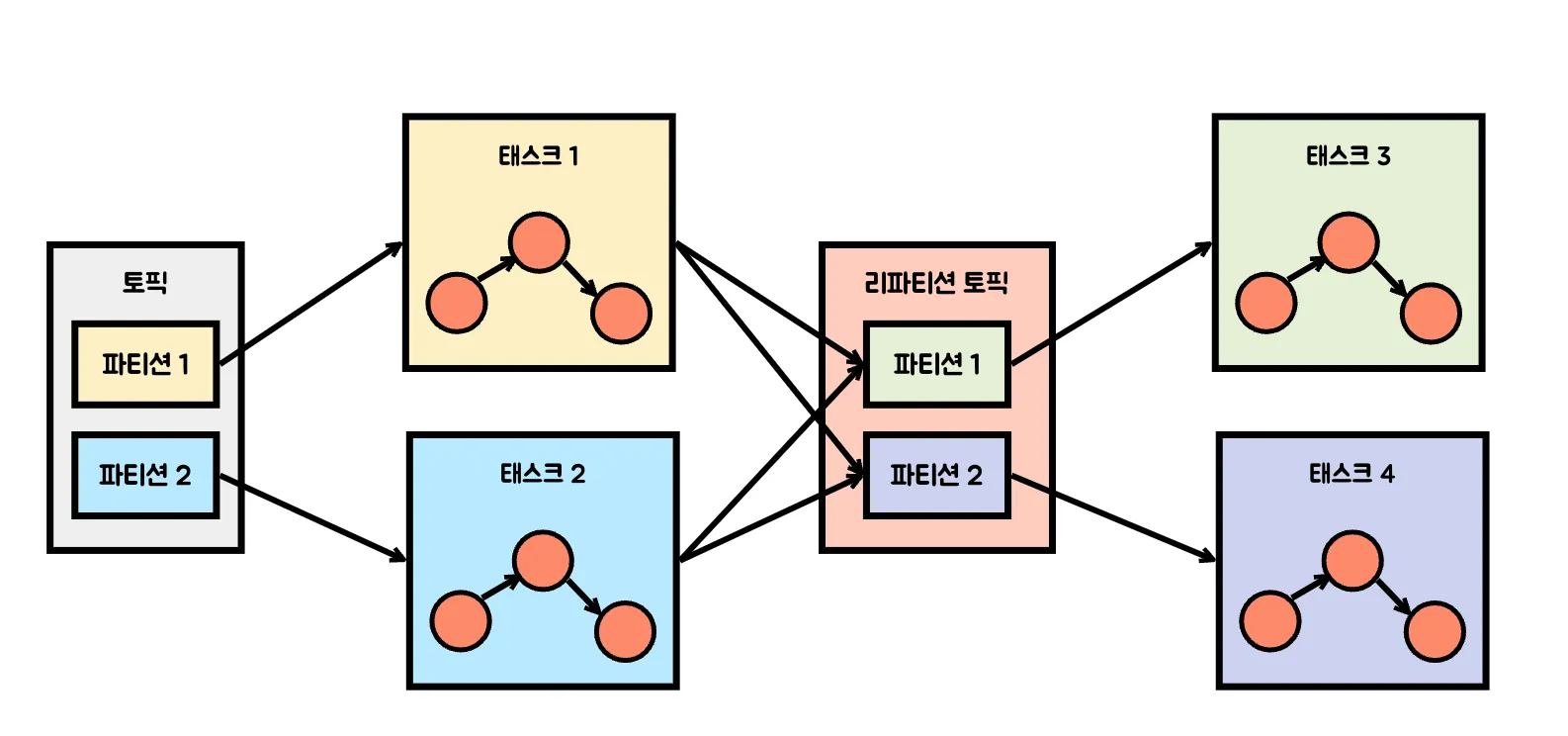
두 번째 서브 토폴로지는 첫 번째의 결과물을 받아서 처리하기 때문에 의존할 수 밖에 없다.
- 하지만❗️ 첫 번째 태스크 집합은 자기 속도대로 데이터를 토픽에 쓰고 두 번째 태스크 집합 역시 자기 속도대로 토픽에서 데이터를 읽어와서 처리하기 때문에 두 태스크 집합은 독립적이고 병렬로 실행된다.
- 태스크 사이에 통신이나 공유된 리소스 같은게 없기 때문에 동일한 스레드나 서버에서 실행될 필요도 없다.
- 파이프라인의 서로 다른 부분 사이에 의존성을 줄여줄 수 있다.
장애 처리하기
⚠️ 애플리케이션에 장애가 발생해서 재시작이 필요한 경우
- 장애가 발생하기 전 마지막으로 커밋된 오프셋을 카프카에서 가져옴으로써 처리하던 스트림의 마지막으로 처리된 지점부터 처리를 재개할 수 있다.
⚠️ 로컬 상태 저장소가 유실되었을 경우(로컬 상태 저장소를 가지고 있던 서버를 새로운 걸로 바꾸는 등)
- 스트림 애플리케이션은 항상 카프카로부터 체인지로그를 카프카에서 읽어옴으로써 로컬 상태 저장소를 복구한다.
✅ 카프카 스트림즈는 태스크 고가용성을 지원하기 위해 카프카의 컨슈머 코디네이션 기능을 사용한다.
⚠️ 태스크에 장애가 발생했지만 다른 스레드 혹은 인스턴스가 멀쩡히 작동 중일 경우
- 해당 태스크는 사용 가능한 다른 스레드에서 재시작하게 된다.
- 컨슈머 그룹에 속한 컨슈머 중에서 장애가 발생한 경우 이 컨슈머에 할당되어 있던 파티션을 남은 컨슈머 중 하나에 할당해줌으로써 장애에 대응하는 것과 유사하다.
- “정확히 한번” 의미 구조, 정적 그룹 멤버쉽이나 협력적 리밸런스와 같은 카프카의 그룹 코디네이션 프로토콜이 개선되면서 카프카 스트림즈 역시 그 혜택을 본다.
⛔️ 카프카는 고가용성 시스템이지만 복구 속도에 대해서도 인지하고 있어야 한다.
태스크를 사용 가능한 다른 스레드가 넘겨받아 처리를 시작할 때, 가장 먼저 저장소 상태(현재 집계중인 윈도우 등)를 복구시켜야 한다.
- 카프카에 저장된 내부 토픽을 다시 읽어와서 카프카 스트림즈의 상태 저장소를 업데이트 하는 식으로 복구할 수 있다.
- 위에 작업을 수행하는 동안은 일부 데이터에 대해서 스트림 처리 작업이 진행되지 않아서 그만큼 가용성은 줄어들고 출력 데이터는 뒤떨어지게 된다.
🤔 복구 시간을 줄이는 문제는 곧 상태를 복구시키는 데 걸리는 시간을 줄이는 문제가 된다.
가장 핵심적인 방법은 모두 카프카 스트림즈 토픽에 매우 강력한 압착 설정을 걸어놓는 것이다.
- min.compaction.lag.ms는 낮추고 세그먼트 크기는 기본값인 1GB 대신 100MB로 낮추기
(각 파티션의 마지막 세그먼트, 즉 활성화된 세그먼트는 압착되지 않는다는 걸 기억하자)
빠른 장애 복구를 위해 Standby Replica를 설정할 것을 권한다.
- Standby Replica: 스트림 처리 애플리케이션에서 현재 작동 중인 태스크를 단순히 따라가기만 하는 태스크로서, 다른 서버에서 현재의 상태를 유지하는 역할을 한다.
- 장애가 발생하면 이 태스크는 이미 거의 최신의 현재 상태를 보유하고 있어서 중단 시간이 거의 없이 바로 처리를 재개할 수 있다.
Run a Kafka Streams Application in Confluent Platform | Confluent Documentation
Kafka Streams makes your stream processing applications elastic and scalable. You can add and remove processing capacity dynamically during application runtime without any downtime or data loss. This makes your applications resilient in the face of failure
docs.confluent.io
'Kafka' 카테고리의 다른 글
| Purgatory (0) | 2025.01.25 |
|---|---|
| 컨슈머 랙(LAG) (1) | 2024.12.02 |
| Kafka ISR(In-Sync-Replica) (1) | 2024.11.15 |