
물리적 스레드와 논리적 스레드
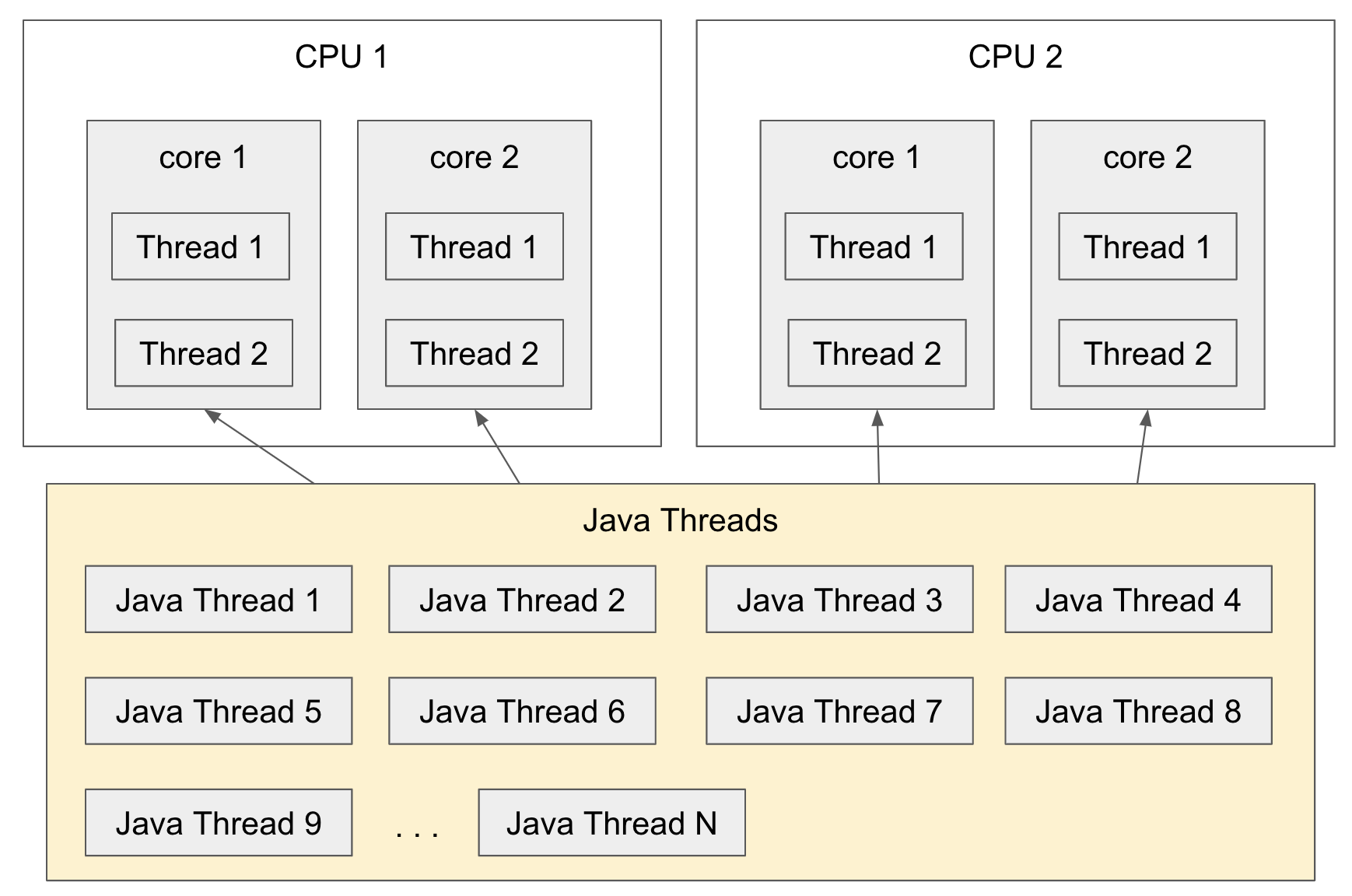
- 물리적인 스레드는 병렬성과 관련이 있으며, 논리적인 스레드는 동시성과 관련이 있다.
물리적 스레드
하나의 코어는 두개의 스레드를 포함하고 있는데 이 두개의 스레드는 물리적인 코어를 논리적으로 나눈 것을 의미한다.
- 이렇게 물리적인 코어를 논리적으로 나눈 코어를 물리적인 스레드라고 한다.
- 쉽게 하드웨어와 관련된 스레드라고 생각할 수 있다.
논리적 스레드
소프트웨어적으로 생성되는 스레드를 의미하며, Java 프로그래밍에서 사용되는 스레드를 말한다.
- 프로세스 내에서 실행되는 세부 작업 단위
- 이론적으로는 메모리가 허용하는 범위 내에서 얼마든지 만들 수 있지만 결국 물리적인 스레드의 가용 범위 내에서 실행될 수 있다.
Scheduler란?
운영체제 레벨에서의 Scheduler는 실행되는 프로그램인 프로세스를 선택하고 실행하는 등 프로세스의 라이프 사이클을 관리해주는 관리자 역할을 한다.
Reactor의 Scheduler는 비동기 프로그래밍을 위해 사용되는 스레드를 관리해 주는 역할을 한다.
- 어떤 스레드에서 무엇을 처리할지 제어
- Scheduler를 사용하면 Race Condition 등의 문제나 복잡한 코드의 문제를 최소화 할 수 있다.
- 스레드의 제어를 대신해 주기 때문에 개발자가 직접 스레드를 제어해야 하는 부담에서 벗어날 수 있다.
Scheduler를 위한 전용 Operator
Reactor에서 Scheduler는 Scheduler 전용 Operator를 통해 사용할 수 있다.
- Operator의 파라미터로 적절한 Scheduler를 전달하면 해당 Scheduler의 특성에 맞는 스레드가 Reactor Sequence에 할당된다.
subscribeOn()
구독이 발생한 직후 실행될 스레드를 지정하는 Operator이다.
- 구독 시점 직후에 실행되기 때문에 원본 Publisher의 동작을 수행하기 위한 스레드라고 볼 수 있다.
@Slf4j
class OnSubscribeExam {
public static void main(String[] args) throws InterruptedException, ExecutionException {
Future<Disposable> submit = Flux.fromArray(new Integer[] {1, 3, 5, 7})
// main 스레드 말고 pool-1-thread-1 스레드에서 실행되는 것을 확인할 수 있다.
// Executors.newFixedThreadPool(3).submit(() -> Flux.fromArray(new Integer[]{1, 3, 5, 7})
.subscribeOn(Schedulers.boundedElastic()) // 구독이 발생한 직후에 원본 Publisher의 동작을 처리하기 위한 스레드를 할당한다.
// .subscribeOn(Schedulers.boundedElastic()) 주석으로 처리하면 처음에 실행된 스레드에서 모든 작업 수행
.doOnNext(data -> log.info("# doOnNext: {}", data)) // 원본 Flux에서 emit되는 데이터를 로그로 출력한다.
.doOnSubscribe(subscription -> log.info("# doOnSubscribe"))
.subscribe(data -> log.info("# onNext: {}", data))
);
submit.get();
Thread.sleep(500L);
}
}
- doOnSubscribe()를 통해서 구독이 발생한 시점에 추가적인 어떤 처리가 필요할 경우 해당 처리 동작을 추가할 수 있다.
- 여기서는 구독이 발생한 시점에 실행되는 스레드가 무엇인지 확인한다.
실행결과
17:18:32.137 [main] INFO - # doOnSubscribe
17:18:32.140 [boundedElastic-1] INFO - # doOnNext: 1
17:18:32.141 [boundedElastic-1] INFO - # onNext: 1
17:18:32.141 [boundedElastic-1] INFO - # doOnNext: 3
17:18:32.141 [boundedElastic-1] INFO - # onNext: 3
17:18:32.141 [boundedElastic-1] INFO - # doOnNext: 5
17:18:32.141 [boundedElastic-1] INFO - # onNext: 5
17:18:32.141 [boundedElastic-1] INFO - # doOnNext: 7
17:18:32.141 [boundedElastic-1] INFO - # onNext: 7
- doOnSubscribe()에서의 동작은 main 스레드에서 동작한다. 이 예제 코드의 최초 실행 스레드가 main 스레드이기 때문이다.
- 이후 subscribeOn()에서 Scheduler를 지정했기 때문에 구독이 발생한 직후부터는 원본 Flux의 동작은 boundedElastic-1 스레드로 바뀌게된다.
publishOn()
Downstream으로 Signal을 전송할 때 실행되는 스레드를 제어하는 역할을 하는 Operator이다.
- publishOn() 기준으로 아래쪽인 Downstream의 실행 스레드를 변경
@Slf4j
class OnPublisherExam {
public static void main(String[] args) throws InterruptedException {
Flux.fromArray(new Integer[] {1, 3, 5, 7})
// .publishOn(Schedulers.parallel()) 여기에 위치시키면 doOnNext도 main 스레드가 아닌 상태에서 확인 가능한데 emit 데이터 확인하기 위해서 존재하는 메서드라서 의미는 없어보임
// .subscribeOn(Schedulers.parallel())
.doOnNext(data -> log.info("# doOnNext: {}", data))
.doOnSubscribe(subscription -> log.info("# doOnSubscribe"))
.publishOn(Schedulers.parallel())
// .parallel(4)
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(500L);
}
}
실행 결과
18:19:15.008 [main] INFO OnPublisherExam -- # doOnSubscribe
18:19:15.013 [main] INFO OnPublisherExam -- # doOnNext: 1
18:19:15.015 [main] INFO OnPublisherExam -- # doOnNext: 3
18:19:15.015 [main] INFO OnPublisherExam -- # doOnNext: 5
18:19:15.015 [main] INFO OnPublisherExam -- # doOnNext: 7
18:19:15.015 [parallel-1] INFO OnPublisherExam -- # onNext: 1
18:19:15.015 [parallel-1] INFO OnPublisherExam -- # onNext: 3
18:19:15.015 [parallel-1] INFO OnPublisherExam -- # onNext: 5
18:19:15.015 [parallel-1] INFO OnPublisherExam -- # onNext: 7
- doOnNext()의 경우, subscribeOn() Operator를 사용하지 않았기 때문에 main 스레드에서 실행
- publishOn() 이후 Downstream의 실행 스레드가 변경되어 parallel-1 스레드에서 실행된다.
parallel()
subscribeOn(), publishOn()의 경우 동시성을 가지는 논리적인 스레드에 해당되지만 parallel() Operator는 병렬성을 가지는 물리적인 스레드에 해당된다.
@Slf4j
class ParallelExam {
public static void main(String[] args) throws InterruptedException {
Flux.fromArray(new Integer[]{1, 3, 5, 7, 9, 11, 13, 15, 17, 19})
.parallel(8) // 4코어 8스레드의 CPU라면 8이상으로 올리더라도 8개 스레드만 호출됨
.runOn(Schedulers.parallel()) // 주석처리를 할 경우 병렬처리가 되지 않음
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(100L);
}
}
parallel() Operator는 emit되는 데이터를 CPU의 논리적인 코어(물리적인 스레드) 수에 맞게 골고루 분배하는 역할만 한다.
- RR 방식으로 CPU 코어 개수만큼의 분배
- 실제로 병렬 작업을 수행할 스레드의 할당은 runOn() Operator가 담당한다.
실행 결과
18:26:51.183 [parallel-1] INFO -- # onNext: 1
18:26:51.183 [parallel-3] INFO -- # onNext: 5
18:26:51.183 [parallel-7] INFO -- # onNext: 13
18:26:51.183 [parallel-4] INFO -- # onNext: 7
18:26:51.183 [parallel-8] INFO -- # onNext: 15
18:26:51.183 [parallel-5] INFO -- # onNext: 9
18:26:51.183 [parallel-6] INFO -- # onNext: 11
18:26:51.183 [parallel-2] INFO -- # onNext: 3
18:26:51.188 [parallel-2] INFO -- # onNext: 19
18:26:51.188 [parallel-1] INFO -- # onNext: 17
- 총 8개의 스레드가 병렬로 실행된다.
publishOn()과 subscribeOn()의 동작 이해
원본 Publisher의 동작과 나머지 동작을 역할에 맞게 분리하고자 subscribeOn()과 publishOn() Operator를 함께 사용하는 경우도 있다.
- Operator를 어떤 식으로 사용하느냐에 따라서 실행 스레드의 동작이 조금씩 달라질 수 있다.
publishOn()과 subscribeOn()을 둘 다 사용하지 않을 때
@Slf4j
class NoPublishSubscribeOn {
public static void main(String[] args) {
Flux
.fromArray(new Integer[] {1, 3, 5, 7})
.doOnNext(data -> log.info("# doOnNext fromArray: {}", data))
.filter(data -> data > 3)
.doOnNext(data -> log.info("# doOnNext filter: {}", data))
.map(data -> data * 10)
.doOnNext(data -> log.info("# doOnNext map: {}", data))
.subscribe(data -> log.info("# onNext: {}", data));
}
}
실행 결과
18:32:19.086 [main] INFO -- # doOnNext fromArray: 1
18:32:19.089 [main] INFO -- # doOnNext fromArray: 3
18:32:19.089 [main] INFO -- # doOnNext fromArray: 5
18:32:19.089 [main] INFO -- # doOnNext filter: 5
18:32:19.089 [main] INFO -- # doOnNext map: 50
18:32:19.089 [main] INFO -- # onNext: 50
18:32:19.089 [main] INFO -- # doOnNext fromArray: 7
18:32:19.089 [main] INFO -- # doOnNext filter: 7
18:32:19.089 [main] INFO -- # doOnNext map: 70
18:32:19.089 [main] INFO -- # onNext: 70
- 모두 main 스레드에서 실행되는 것을 볼 수 있다.
PublishOn()만 사용하는 경우
@Slf4j
class OnlyOnePublishOn {
public static void main(String[] args) throws InterruptedException {
Flux
.fromArray(new Integer[] {1, 3, 5, 7})
.doOnNext(data -> log.info("# doOnNext fromArray: {}", data))
.publishOn(Schedulers.parallel())
.filter(data -> data > 3)
.doOnNext(data -> log.info("# doOnNext filter: {}", data))
.map(data -> data * 10)
.doOnNext(data -> log.info("# doOnNext map: {}", data))
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(500L);
}
}
실행 결과
18:34:05.732 [main] INFO -- # doOnNext fromArray: 1
18:34:05.735 [main] INFO -- # doOnNext fromArray: 3
18:34:05.735 [main] INFO -- # doOnNext fromArray: 5
18:34:05.735 [main] INFO -- # doOnNext fromArray: 7
18:34:05.735 [parallel-1] INFO -- # doOnNext filter: 5
18:34:05.735 [parallel-1] INFO -- # doOnNext map: 50
18:34:05.735 [parallel-1] INFO -- # onNext: 50
18:34:05.735 [parallel-1] INFO -- # doOnNext filter: 7
18:34:05.735 [parallel-1] INFO -- # doOnNext map: 70
18:34:05.735 [parallel-1] INFO -- # onNext: 70
- publishOn() 기준으로 아래쪽인 filter(downstream)부터 parallel-1 스레드에서 실행되었다.
publishOn()를 2번 사용하는 경우
@Slf4j
class OnlyTwoPublishOn {
public static void main(String[] args) throws InterruptedException {
Flux
.fromArray(new Integer[] {1, 3, 5, 7})
.doOnNext(data -> log.info("# doOnNext fromArray: {}", data))
.publishOn(Schedulers.parallel())
.filter(data -> data > 3)
.doOnNext(data -> log.info("# doOnNext filter: {}", data))
.publishOn(Schedulers.parallel())
.map(data -> data * 10)
.doOnNext(data -> log.info("# doOnNext map: {}", data))
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(500L);
}
}
실행 결과
18:37:18.771 [main] INFO -- # doOnNext fromArray: 1
18:37:18.775 [main] INFO -- # doOnNext fromArray: 3
18:37:18.775 [main] INFO -- # doOnNext fromArray: 5
18:37:18.775 [main] INFO -- # doOnNext fromArray: 7
18:37:18.775 [parallel-2] INFO -- # doOnNext filter: 5
18:37:18.775 [parallel-2] INFO -- # doOnNext filter: 7
18:37:18.775 [parallel-1] INFO -- # doOnNext map: 50
18:37:18.775 [parallel-1] INFO -- # onNext: 50
18:37:18.775 [parallel-1] INFO -- # doOnNext map: 70
18:37:18.776 [parallel-1] INFO -- # onNext: 70
- 첫 번째 publishOn()의 downstream인 filter는 parallel-2 스레드
- 두 번째 publishOn()의 downstream인 map 부터는 parallel-1 스레드
publishOn()와 subscribeOn()을 함께 사용하는 경우
subscribeOn() Operator와 publishOn() Operator를 함께 사용하면 원본 Publisher에서 데이터를 emit하는 스레드와 emit된 데이터를 가공 처리하는 스레드를 적절하게 분리할 수 있다.
@Slf4j
class WithPublishSubscribeOn {
public static void main(String[] args) throws InterruptedException {
Flux
.fromArray(new Integer[] {1, 3, 5, 7})
.subscribeOn(Schedulers.boundedElastic())
.doOnNext(data -> log.info("# doOnNext fromArray: {}", data))
.filter(data -> data > 3)
.doOnNext(data -> log.info("# doOnNext filter: {}", data))
.publishOn(Schedulers.parallel())
.map(data -> data * 10)
.doOnNext(data -> log.info("# doOnNext map: {}", data))
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(500L);
}
}
실행 결과
18:40:06.760 [boundedElastic-1] INFO -- # doOnNext fromArray: 1
18:40:06.762 [boundedElastic-1] INFO -- # doOnNext fromArray: 3
18:40:06.762 [boundedElastic-1] INFO -- # doOnNext fromArray: 5
18:40:06.763 [boundedElastic-1] INFO -- # doOnNext filter: 5
18:40:06.763 [boundedElastic-1] INFO -- # doOnNext fromArray: 7
18:40:06.763 [boundedElastic-1] INFO -- # doOnNext filter: 7
18:40:06.765 [parallel-1] INFO -- # doOnNext map: 50
18:40:06.766 [parallel-1] INFO -- # onNext: 50
18:40:06.766 [parallel-1] INFO -- # doOnNext map: 70
18:40:06.766 [parallel-1] INFO -- # onNext: 70
- 구독이 발생한 직후에, 실행될 스레드를 지정해 주었기 때문에 publishOn() Operator 이전까지는 boundedElastic-1 스레드에서 실행된다.
- publishOn() 이후는 parallel-1 스레드에서 실행된다.
Schedule의 종류
Schedulers.immediate()
별도의 스레드를 추가적으로 생성하지 않고, 현재 스레드에서 작업을 처리하고자 할 때 사용할 수 있다.
@Slf4j
class Immediate {
public static void main(String[] args) throws InterruptedException {
Flux
.fromArray(new Integer[] {1, 3, 5, 7})
.doOnNext(data -> log.info("flux data: {}", data))
.publishOn(Schedulers.parallel())
.filter(data -> data > 3)
.doOnNext(data -> log.info("# doOnNext filter: {}", data))
.publishOn(Schedulers.immediate())
.map(data -> data * 10)
.doOnNext(data -> log.info("# doOnNext map: {}", data))
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(200L);
}
}
실행 결과
19:17:48.656 [main] INFO -- flux data: 1
19:17:48.660 [main] INFO -- flux data: 3
19:17:48.660 [main] INFO -- flux data: 5
19:17:48.660 [main] INFO -- flux data: 7
19:17:48.660 [parallel-1] INFO -- # doOnNext filter: 5
19:17:48.660 [parallel-1] INFO -- # doOnNext map: 50
19:17:48.660 [parallel-1] INFO -- # onNext: 50
19:17:48.660 [parallel-1] INFO -- # doOnNext filter: 7
19:17:48.660 [parallel-1] INFO -- # doOnNext map: 70
19:17:48.660 [parallel-1] INFO -- # onNext: 70
- publishOn()이 1번 사용됬기 때문에 추가 스레드를 생성하지 않고 parallel-1 스레드가 현재 스레드가 된다.
굳이 Schedulers.immediate()를 사용할 필요가 있을까?
공통의 역할을 하는 API이고, 해당 API의 파라미터로 Scheduler를 전달한다고 가정해보자
- 이 API를 사용하는 입장에서 map() 이후의 Operator 체인 작업은 원래 실행되던 스레드에서 실행하게 하고 싶을 때도 있을 것이다.
- Scheduler가 필요한 API가 있긴 한데 별도의 스레드를 추가 할당하고 싶지 않은 경우에 사용할 수 있다.
Schedulers.single()
스레드 하나만 생성해서 Scheduler가 제거되기 전까지 재사용하는 방식이다.
@Slf4j
class Single {
public static void main(String[] args) throws InterruptedException {
// doTask()를 두번 호출하더라도 첫번째 호출에서 이미 생성된 스레드를 재사용한다.
doTask("task1")
.subscribe(data -> log.info("# onNext: {}", data));
doTask("task2")
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(200L);
}
private static Flux<Integer> doTask(String taskName) {
return Flux.fromArray(new Integer[] {1, 3, 5, 7})
.publishOn(Schedulers.single())
.filter(data -> data > 3)
.doOnNext(data -> log.info("# {} doOnNext filter: {}", taskName, data))
.map(data -> data * 10)
.doOnNext(data -> log.info("# {} doOnNext map: {}", taskName, data));
}
}
실행 결과
19:25:05.636 [single-1] INFO -- # task1 doOnNext filter: 5
19:25:05.640 [single-1] INFO -- # task1 doOnNext map: 50
19:25:05.640 [single-1] INFO -- # onNext: 50
19:25:05.641 [single-1] INFO -- # task1 doOnNext filter: 7
19:25:05.641 [single-1] INFO -- # task1 doOnNext map: 70
19:25:05.641 [single-1] INFO -- # onNext: 70
19:25:05.642 [single-1] INFO -- # task2 doOnNext filter: 5
19:25:05.642 [single-1] INFO -- # task2 doOnNext map: 50
19:25:05.642 [single-1] INFO -- # onNext: 50
19:25:05.642 [single-1] INFO -- # task2 doOnNext filter: 7
19:25:05.642 [single-1] INFO -- # task2 doOnNext map: 70
19:25:05.642 [single-1] INFO -- # onNext: 70
- doTask()를 두번 호출하더라도 첫번째 호출에서 이미 생성된 스레드를 재사용한다.
- single-1 스레드에서 모두 처리되는 것을 볼 수 있다.
Schedulers.newSingle()
Schedulers.single()과 다르게 호출할때마다 매번 새로운 스레드 하나를 생성한다.
@Slf4j
class NewSingle {
public static void main(String[] args) throws InterruptedException {
doTask("task1")
.subscribe(data -> log.info("# onNext: {}", data));
doTask("task2")
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(200L);
}
private static Flux<Integer> doTask(String taskName) {
return Flux.fromArray(new Integer[] {1, 3, 5, 7})
.publishOn(Schedulers.newSingle("new-single", true))
.filter(data -> data > 3)
.doOnNext(data -> log.info("# {} doOnNext filter: {}", taskName, data))
.map(data -> data * 10)
.doOnNext(data -> log.info("# {} doOnNext map: {}", taskName, data));
}
}
newSingle에 넘겨주는 인자는 첫 번째 생성할 스레드의 이름 두 번째 데몬스레드 동작 여부이다.
.publishOn(Schedulers.newSingle("new-single", true))
데몬(Daemon) 스레드
- 데몬 스레드는 보조 스레드라고도 불리는데, 주 스레드가 종료되면 자동으로 종료되는 특성이 있다.
- 이번 예제는 Schedulers.newSingle()에 true로 설정해서 main 스레드가 종료되면 자동으로 종료된다.
실행 결과
19:29:19.267 [new-single-1] INFO -- # task1 doOnNext filter: 5
19:29:19.267 [new-single-2] INFO -- # task2 doOnNext filter: 5
19:29:19.272 [new-single-1] INFO -- # task1 doOnNext map: 50
19:29:19.272 [new-single-2] INFO -- # task2 doOnNext map: 50
19:29:19.272 [new-single-1] INFO -- # onNext: 50
19:29:19.272 [new-single-2] INFO -- # onNext: 50
19:29:19.272 [new-single-1] INFO -- # task1 doOnNext filter: 7
19:29:19.272 [new-single-2] INFO -- # task2 doOnNext filter: 7
19:29:19.272 [new-single-1] INFO -- # task1 doOnNext map: 70
19:29:19.272 [new-single-2] INFO -- # task2 doOnNext map: 70
19:29:19.272 [new-single-1] INFO -- # onNext: 70
19:29:19.272 [new-single-2] INFO -- # onNext: 70
- doTask()를 호출할때마다 새로운 스레드 하나를 생성해서 각각의 작업을 처리하는 것을 볼 수 있다.
그외 Scheduler 종류
Schedulers.boundedElastic()
ExecutorService 기반의 스레드 풀을 생성한 후, 그 안에서 정해진 수만큼의 스레드를 사용하여 작업을 처리하고 작업이 종료된 스레드는 반납하여 재사용한다.
- 기본적으로 CPI 코어 수 x 10 만큼의 스레드를 생성한다.
- 풀에 있는 모든 스레드가 작업을 처리하고 있다면 이용 가능한 스레드가 생길 때까지 최대 100,000개의 작업이 큐에서 대기할 수 있으니 주의하자
- Blocking I/O 작업을 효과적으로 처리하기 위한 방식이다.
사용하는 이유
실행시간이 긴 Blocking I/O 작업이 포함된 경우, 다른 Non-Blocking 처리에 영향을 주지 않도록 전용 스레드를 할당해서 Blocking I/O 작업을 처리하기 때문에 처리 시간을 효율적으로 사용할 수 있다.
Schedulers.parallel()
Non-Blocking I/O에 최적화되어 있는 Scheduler로서 CPU 코어 수만큼의 스레드를 생성한다.
Schedulers.fromExecutorService()
기존에 이미 사용하고 있는 ExecutorService가 있다면 이 ExecutorService로부터 Scheduler를 생성하는 방식이다.
- ExecutorService로부터 직접 생성할 수도 있지만 Reactor에서는 이 방식을 권장하지 않는다.
Schedulers.newXXX()
single(), boundedElastic(), parallel()은 Reactor에서 제공하는 디폴트 Scheduler 인스턴스를 사용한다.
- 하지만 필요하다면 newSingle(), newBoundedElastic(), newParallel() 메서드를 이용해서 새로운 Scheduler 인스턴스를 생성할 수 있다.
- 스레드 이름, 생성 가능한 디폴트 스레드 개수, 스레드 유휴 시간, 데몬 스레드로의 동작 여부 등을 직접 지정해서 커스텀 스레드 풀을 새로 생성할 수 있다.
'Reactive Programming' 카테고리의 다른 글
| Debugging (0) | 2025.01.02 |
|---|---|
| Context (0) | 2024.12.22 |
| Sinks (1) | 2024.12.04 |
| Backpressure (0) | 2024.11.19 |
| Cold Sequence와 Hot Sequence (0) | 2024.11.19 |