
스프링 데이터 레디스 레퍼런스 번역 문서입니다.
스프링 데이터 레디스 프로젝트는 스프링 개념을 키밸류 스타일의 데이터 저장소를 사용하는 개발솔루션에 적용한 것입니다. 우리는 메시지를 송수신하는 데 있어
arahansa.github.io
Cache란?
자주 사용하는 데이터나 값을 미리 복사해 놓는 임시 장소를 가리킨다. 아래와 같은 저장공간 계층 구조에서 확인할 수 있듯이, 캐시는 저장 공간이 작고 비용이 비싼 대신 빠른 성능을 제공한다.
Cache는 아래와 같은 경우에 사용을 고려하면 좋다.
접근 시간에 비히 원래 데이터를 접근하는 시간이 오래 걸리는 경우(서버의 균일한 API 데이터)
반복적으로 동일한 결과를 돌려주는 경우(이미지나 썸네일 등)
Long Tail 법칙은 20%의 요구가 시스템 리소스의 대부분을 사용한다는 법칙이다. 그렇기 때문에 20%의 기능에 Cache를 이용함으로써 리소스 사용량은 대폭 줄이고, 성능은 대폭 향상시킬 수 있다.
[REDIS] 📚 캐시(Cache) 설계 전략 지침 💯 총정리
Redis - 캐시(Cache) 전략 캐싱 전략은 웹 서비스 환경에서 시스템 성능 향상을 기대할 수 있는 중요한 기술이다. 일반적으로 캐시(cache)는 메모리(RAM)를 사용하기 때문에 데이터베이스 보다 훨씬 빠
inpa.tistory.com
캐시 서버는 Look aside cache 패턴과 Write Back 패턴이 존재합니다.
- Look aside cache
1. 클라이언트가 데이터를 요청
2. 웹서버는 데이터가 존재하는지 Cache 서버에 먼저 확인
3. Cache 서버에 데이터가 있으면 DB에 데이터를 조회하지 않고 Cache 서버에 있는 결과값을 클라이언트에게 바로 반환 (Cache Hit)
4. Cache 서버에 데이터가 없으면 DB에 데이터를 조회하여 Cache 서버에 저장하고 결과값을 클라이언트에게 반환 (Cache Miss)
- Write Back
1. 웹서버는 모든 데이터를 Cache 서버에 저장
2. Cache 서버에 특정 시간 동안 데이터가 저장됨
3. Cache 서버에 있는 데이터를 DB에 저장
4. DB에 저장된 Cache 서버의 데이터를 삭제
* insert 쿼리를 한 번씩 500번 날리는 것보다 insert 쿼리 500개를 붙여서 한 번에 날리는 것이 더 효율적이라는 원리입니다.
* 이 방식은 들어오는 데이터들이 저장되기 전에 메모리 공간에 머무르는데 이때 서버에 장애가 발생하여 다운된다면 데이터가 손실될 수 있다는 단점이 있습니다.
In-Memory
캐싱 방법은 기존 DB와는 다르게 효율적인 방식으로 데이터를 접근하여 성능을 높입니다. 주로 사용하는 RDBMS는 무결성을 위해 Disk에서 데이터를 읽어옵니다. 하지만 캐싱 기법을 사용하는 기술들은 메모리에서 데이터를 가져옵니다.
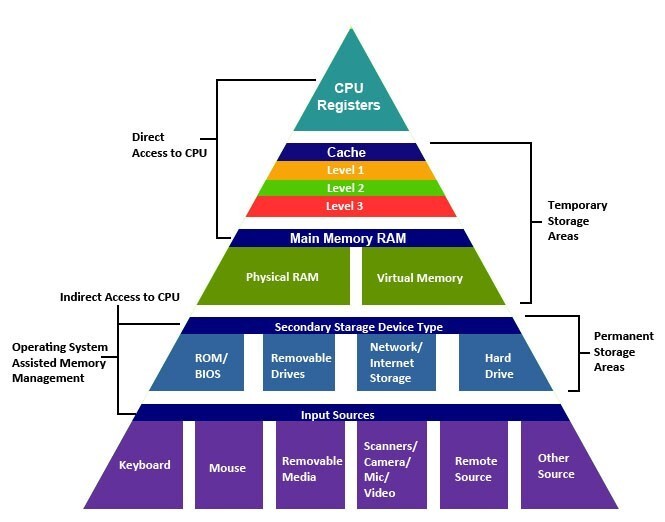
- 상위의 계층일수록 접근 속도가 빠르며, 비용이 많이 듭니다. 반대로 아래의 계층은 접근속도가 느리고 비용이 적게 듭니다.
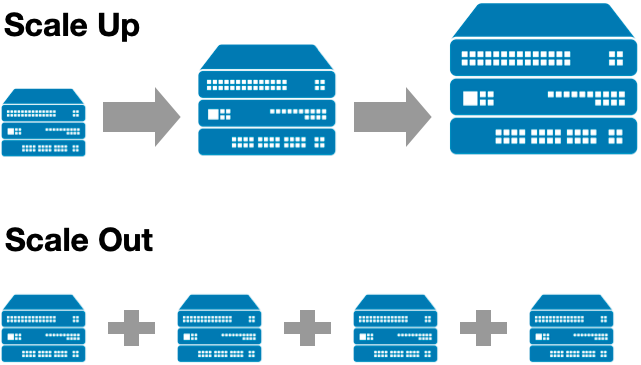
기술의 발전으로 많은 데이터를 빠르게 연산하는 방법이 고도화가 되었습니다. 하지만 Disk의 성능을 향상시키는 방법으로 CPU,메모리,하드디스크를 향상시키는 스케일업과 서버의 수를 늘리는 스케일아웃이 있었지만 물리적인 한계와 비효율적인 자원낭비가 심했습니다. 그래서 기술적인 방법으로 해결하는 방법을 모색했고 HDD, SDD가 속해있는 Disk 계층보다도 효용성을 중시할 수 있는 Main Memory의 사용 비중이 높아지고 발전했습니다.
NoSQL
분산 환경에서 대량의 데이터를 빠르게 처리하기 위해서는 RDBMS는 적합하지 않았습니다. 대안으로 나온 NoSQL은 데이터를 빠르게 처리할 수 있는 구조와 함께 스케일 아웃에 따라 선형적인 성능의 발전을 확인할 수 있는 데이터 베이스입니다.
- 다중 서버 환경에서의 세션 불일치 문제
NoSQL 특징
- 거대한 Map으로서 key-value 형식을 지원한다.
- RDBMS가 데이터의 관계를 Foreign Key 등으로 정의하고 Join 등 관계형 연상을 하지만 NoSQL은 관계를 정의하지 않는다.
- 대용량 데이터 저장을 한다.
- 분산형 구조를 통해 여러대의 서버에 분산하여 저장하고 상호복제하여 데이터 유실이나 서비스 중지에 대비한다.
- Schema-less
- 읽기 작업보다 쓰기 작업이 더 빠르며, 일반적으로 RDBMS에 비하여 쓰기와 읽기 성능이 빠르다.
NoSQL이 분산환경에 최적화 되어있는 이유는 CAP 이론으로 확인할 수 있습니다.
[Database] CAP 정리 - Azderica
[Database] CAP 정리 Posted 9. February 2021. 4 min read. CAP 정리 DB에 대해 공부하다 보면, CAP 이론에 대해 듣게 됩니다. 비록 이야기가 조금 있기는 하지만 그래도 CAP에 대해 개념을 정리합니다. CAP 란. CAP이
azderica.github.io
Redis
앞서 얘기한 여러 이점을 활용하기 하기위해서 우리는 캐싱 전략에 적합한 In-Memory 기반의 NoSQL 데이터베이스인 레디스를 사용합니다.
운영 중인 웹 서버에서 key-value 형태의 데이터 타입을 처리해야 하고, I/O가 비번히 발생해 다른 저장 방식을 사용하면 효율이 떨어지는 경우에 사용한다.
Redis의 개념
레디스는 Remote Dictionary Server의 약자입니다. Dictionary는 Java, Javascript에서의 Hashmap, Python에서의 Dictionary와 같이 Key-value를 사용해서 데이터를 반환하는 자료구조입니다.
- Key, Value 구조이기 때문에 쿼리를 사용할 필요가 없습니다.
- 데이터를 디스크에 쓰는 구조가 아니라 메모리에서 데이터를 처리하기 때문에 속도가 빠릅니다.
- String, Lists, Sets, Sorted Sets, Hashes 자료 구조를 지원합니다.
- Single Threaded 입니다.
: 한 번에 하나의 명령만 처리할 수 있습니다. 그렇기 때문에 중간에 처리 시간이 긴 명령어가 들어오면 그 뒤에 명령어들은 모두 앞에 있는 명령어가 처리될 때까지 대기가 필요합니다.
(하지만 get, set 명령어의 경우 초당 10만 개 이상 처리할 수 있을 만큼 빠릅니다.)
Redis는 모든 데이터를 메모리에 영구적(임의로 삭제하거나 Expire를 설정하지 않으면)으로 저장하고 조회합니다. 단, 다른 In-Memory 데이터베이스인 Memcached와 기능적인 차이가 있습니다. Redis는 다양한 자료구조를 지원합니다.
Redis 특징
- key-value 스토어 : 단순 스트링에 대한 Key-Value 구조를 지원
- Key, Value 모두 512MB
- 바이너리 데이터 쓰기 가능
- 컬렉션 지원 : List, Set, Sorted Set, Hash 등의 자료구조를 지원함
- Pub/Sub 지원 : Publish/Subscribe 모델을 지원.
- 메시지 브로커로 사용
- 디스크 저장
- 현재 메모리 상태의 스냅샷을 남기는 기능 'RDB' / 지금까지 실행된 업데이트 관련 명령어의 집합 'AOF'
- RDB : 메모리 내용을 저장하는 기능 외에는 아무것도 지원하지 않는다. (데이터베이스가 아니다)
- AOF (Append Only File) : set / del 등의 업데이트 관련 명령어를 그대로 기록함
- 복제 (replication) : 다른 노드에서 해당 내용을 복제할 수 잇는 마스터/슬레이브 구조를 지원
- 빠른 속도 : 이상의 기능을 지원하면서도 초당 100,000 QPS (Queries Per Second) 수준의 높은 성능을 자랑
- Expire : 레디스는 In-Memory인 만큼 메모리에 저장될 수 있는 데이터가 한정적입니다. 따라서 데이터를 주기적으로 삭제해주는 로직이 필요한데, expire은 데이터를 입력할 때 사용기한을 직접 설정해주는 기능입니다.
Redis use case
- Remote Data Store : a,b,c 서버에서 데이터를 공유하고 싶을 때 사용
- Cache
- 인증 토큰 등을 저장
- 랭킹 보드 사용(sorted set)
- 유저 api limit
- 잡 큐(list), 메시지 브로커
Redis 자료구조

Redis는 아래의 자료구조를 공식적으로 지원하고 있습니다.
- Strings : Vinary-safe한 기본적인 key-value 구조
- Lists : String element의 모음, 순서는 삽입된 순서를 유지하며 기본적인 자료구로 Linked List를 사용
- Sets : 유일한 값들의 모임인 자료구조, 순서는 유지되지 않음
- Sorted sets : Sets 자료구조에 score라는 값을 추가로 두어 해당 값을 기준으로 순서를 유지
- Hahses : 내부에 key-value 구조를 하나더 가지는 Reids 자료구조
- Bit arrays(bitMaps) : bit array를 다를 수 있는 자료구조
- HyperLogLogs : HyperLogLog는 집합의 원소의 개수를 추정하는 방법, Set 개선된 방법
- Streams : Redis 5.0 에서 Log나 IoT 신호와 같이 지속적으로 빠르게 발생하는 데이터를 처리하기 위해서 도입된 자료구조
Strings
Strings 타입은 Redis에서 가장 기본적인 Type 입니다. Key-value 형식이며 binary safe한 특징을 가지고 있어, 어떠한 데이터의 종류도 key, value가 될 수 있습니다.

- 값의 최대 길이는 512MB 입니다.
- INCR, DECR, INCRBY 명령어를 통해 thread safe한 Atomic Counter를 구현할 수 있다.
- APPEND 명령어를 통해 값을 이어나갈 수 있습니다.
- GETRANGE, SETRANGE 명령어를 통해 랜덤 액세스가 가능합니다. 랜덤 액세스는 값의 어느 위치든 index를 통해 접근할 수 있는 기능입니다. (값의 중간을 조회할 수 있다.)
set [key] [value]
get [key]
set [key] [value] ex [seconds]
setex [key] [value] [seconds]
# -1은 설정 x, -2는 만료
ttl [key]
append [key] [append value]
getrange [key] name [from index] [to index]
setrange [key] [index] [value]
incr [key]
decr [key]Lists
Lists는 Linked List와 유사한 형태로 데이터가 저장되는 Redis에서 제공하는 자료구조입니다. 따라서 처음과 마지막 부분에 element를 추가 / 삭제 / 조회하는 것은 O(1)의 속도를 가지지만 중간 특정 index를 조회할 때는 O(N)의 속도를 가지는 단점을 가지고 있습니다. 따라서 중간의 값을 가져올 때는 Sorted Set 자료구조가 용이합니다.

- lpush, rpush를 통해 각각 가장 앞에 오는 값과, 가장 마지막에 오는 값을 삽입할 수 있습니다.
- 소셜 네트워크에서 타임라인 같은 기능을 구현할 때 lpush와 lrange를 통해 일정한 크기의 리스트를 빠르게 반환할 수 있습니다.
- lpush와 ltream을 사용해서 Lists의 크기를 유지할 수 있다.
- lpush와 lpop를 통해 message를 전달하는 queue의 형태로 사용할 수 있습니다.
lpush [key] [element]
rpush [key] [element]
lrange [key] [from index] [to index]
# 리스트 전체
lrange [key] 0 -1
Sets
Redis의 Sets는 순서가 보장되지 않는 Strings의 집합 자료구조입니다. 기본적으로 추가, 삭제, element의 존재 유무 확인 등에 대해서 O(1)의 속도를 보장합니다. 또한 Set이기 때문에 동일한 value는 중복 제거가 됩니다.
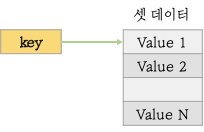
- 트래킹에 사용될 수 있습니다. 애플리케이션에 접근한 IP, 세션 리스트를 관리하고자 할 때 중복을 허용하지 않는 Sets 자료구조를 활용할 수 있습니다.
- 게시글의 태그를 표현하기 좋습니다.
- Sets는 Sets간의 합집합, 차집합 등 집합연산을 사용할 수 있습니다.
- Sets의 요소를 랜덤으로 뽑는 spop, srandmember 등의 명령어가 있습니다.
# 이미 존재하면 0, 추가가 완료되면 1 반환
sadd [key] [element]
# 전체 멤버 반환
smembers [key]
Sorted Sets
Sorted Sets는 Sets 자료구조에 Score를 추가로 기록하여 score가 낮은순서부터 높은순서대로 정렬되는 자료구조입니다. 동일한 값은 오지 못하며 Score는 동일할 수 있습니다.
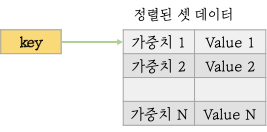
셋 데이터와 동일한 특징을 가지나 저장된 요소에 가중치를 부여하여 작은 값부터 큰 값 정렬을 제공합니다. 단 같은 가중치인 경우는 순서가 변경될 수 있습니다. 가중치에 입력할 수 있는 값은 정수 또는 float 타입입니다.
- 랭킹 리스트를 표현할 때 사용될 수 있습니다. zadd 명령어를 통해 score와 이름을 함께 보내면 쉽고 빠르게 정렬되고 유일한 값을 가지는 자료구조를 만들 수 있습니다. 또한 찾을 때는 zrank, zrange 명령어를 이용할 수 있습니다.
- Sorted Sets는 자주 Redis에 저장된 데이터의 index를 저장하기 위해서 사용되기도 합니다. hashes에 user를 담아둔다고 한다면 이 값을 나이순으로 정렬하던지 할 수 있습니다.
zadd [key] [score] [value]
# 전체 리스트 반환
zrange [key] 0 -1
# 전체 리스트 반환 with score
zrange [key] 0 -1 withscores
Sorted Sets 이슈
sorted형의 score는 정수형이아니라 double형태인 실수형이다.
IEEE 754 표준에는 32비트(float - 단밀도, 필수구현) 형식 뿐 아니라 64비트(double - 배밀도) 등 타 형식들도 정의되어 있습니다. (지수부, 가수부 저장방식)
우리가 코드에서 사용한 자료형의 숫자는 2진법 기반이기 때문에 1/10을 정확하게 표현할 수 없다. ( 즉 근사값이 저장됨)
특정 범위를 넘어선 Long값 같은경우도 문제가 발생하기 때문에 어떤 특정정수는 실수에서 표현이 안될 수 있다.
순서가 명확해야되는데 이러한 이슈로 인해서 문제가 발생할 수 있다.
JavaScript로 통신하는 경우에 숫자로 받으면 안되고 String으로 받아서 처리하자
Hashes
해시는 key-value 구조에서 value에 또다른 key-value Map을 가질 수 있게하는 자료구조입니다.
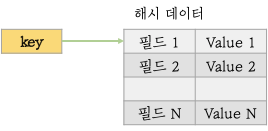
- 해시 데이터에는 2^32-1개의 필드를 저장할 수 있습니다.
hset [hash key] [key] [value]
hget [hash key] [key]
hgetall [hash key]
Single Thread
같은 In-Memory DB이면서 NoSQL 데이터베이스인 Memcached와 레디스의 가장 큰 차이점 중 하나는 Redis는 싱글 스레드로 운용이 된다는 점입니다. 싱글 스레드의 강력한 강점은 원자성(Atomic)을 보장합니다.
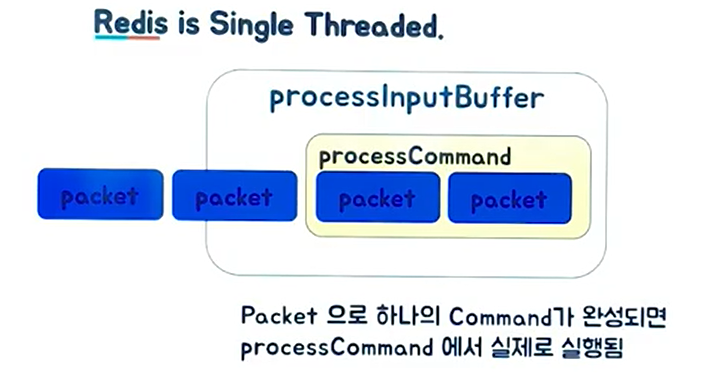
따라서 멀티 스레드를 사용할 때 문제가 되는 Race Condition과 Context Swtiching이 발생하지 않습니다.
- Race Condition과 Context Switching은 공유되는 자원을 다른 쓰레드 환경에서 동시에 접근할 때 동기화 메커니즘 없이 접근하여 발생하는 문제입니다.
싱글 스레드이기 때문에 명령을 수행할 때 시간 복잡도를 필수적으로 고려해야 합니다. (O(N) 연산이 수행되는 명령어를 조심하자!)
- 한 번에 하나의 명령만 처리할 수 있습니다. 그렇기 때문에 중간에 처리 시간이 긴 명령어가 들어오면 그 뒤에 명령어들은 모두 앞에 있는 명령어가 처리될 때까지 대기가 필요합니다.
(하지만 get, set 명령어의 경우 초당 10만 개 이상 처리할 수 있을 만큼 빠릅니다.)
대표적인 실수 사례
자료구조의 시간복잡도를 고려하여 redis를 활용해야지 이슈를 방지할 수 있습니다.
- key가 백만개 이상인데 keys사용하는 경우
- scan 명령어로 긴 명령을 짧은 여러번의 명령으로 변경 가능
- 아이템이 몇 만개든 hash, sorted set, set에서 데이터를 가져오는 경우
- 일부만 가져오기
- 큰 collection을 작은 여러 collection으로 나눠서 저장
- Spring security oath RedisTokenStore 이슈
- 최신 버전에서는 set(o(1))로 해결
O(N) 명령어
- keys
- FLUSHALL, FLUSHDB
- Delete Collections
- Get All Collections
Redis와 Memcached 비교

| Memcached | Redis | |
| 스레드 | 멀티 스레드 | 싱글 스레드 |
| 자료 구조 | string과 integers 지원 | list, string, hashes, sorted sets, bitmaps 등 |
| 데이터 저장 | Only Memory | Memory, Disk |
| 처리속도 | 디스크를 사용하지 않아 redis보다 빠르다. | Memcached보다 느리지만 큰 차이는 없음. |
| Replication | 지원 안함 | 지원 |
| Partitioning method | 지원 안함 | 지원 |
| 영속성(Persistence) | 지원 안함 | 영속성있는 데이터 사용 |
- 영속성은 프로그램이 중단되어도 데이터가 살아있는지를 뜻한다.
- 기본적으로 Redis는 In-Memory DB여서 프로그램이 중단되면 데이터가 날라간다.
- 하지만 redis는 일정 시점에 DB의 데이터를 스냅샷으로 저장하고 그동안 기록된 커맨드를 기록하여 이 데이터를 다시 복구하는 기능이 있다.
- RDB, AOF에 대해 알아보면 Redis의 영속성에 대해서 알 수 있다.
- 따라서 설정에 따라 영속성있는 데이터를 활용할 수 있다.
너무 감사한 강의였다. 아직 모르는 단어도 많고 이해하기 힘들지만 시간이 지나 지식이 쌓이면 더 많이 지식을 얻을 수 있을꺼 같다
[Redis] Redis 자료구조 알아보기
안녕하세요. 이전 [Redis] Redis의 기본 명령어 포스팅에서 Redis의 기본적인 명령어와 이와 연관된 자료구조에 대해서 간단하게 알아본적이 있습니다. Redis는 다양한 자료구조를 기본적으로 제공하
sabarada.tistory.com
레디스(Redis) 알아보기
2010년 트위터, 페이스북, 아마존 등의 글로벌 기업들이 급부상했습니다. 모바일 등의 클라이언트 증가로 사용자와의 인터랙티브가 많아졌습니다. 이렇게 많은 요청과 응답이 왔을 때 기존 RDBMS
velog.io
Redis란? 레디스의 기본적인 개념 (인메모리 데이터 구조 저장소)
Redis란? Key, Value 구조의 비정형 데이터를 저장하고 관리하기 위한 오픈 소스 기반의 비관계형 데이터 베이스 관리 시스템 (DBMS)입니다. 데이터베이스, 캐시, 메세지 브로커로 사용되며 인메모리
wildeveloperetrain.tistory.com
'Web' 카테고리의 다른 글
| 실시간, 양방향 데이터 통신 (0) | 2024.01.06 |
|---|---|
| OAuth2(Open Authorization) (0) | 2023.04.08 |
| JWT(Json Web Token) (0) | 2023.03.23 |
| HTTP 메소드 (0) | 2022.12.29 |
| 상태 코드(2) (0) | 2022.12.29 |