
일반적으로 코드 가독성이 좋다는 것은 '어떤 코드를 다른 사람도 쉽게 이해할 수 있음'을 의미한다.
익명 클래스를 람다 표현식으로 리팩터링하기
하나의 추상 메서드를 구현하는 익명 클래스는 람다 표현식으로 리팩터링할 수 있다.
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Hi~");
}
}).start();
new Thread(()-> System.out.println("Hi~")).start();익명 클래스를 람다 표현식으로 변환하기 위한 조건
익명 클래스에서 사용한 this와 super는 람다 표현식에서 다른 의미를 갖는다.
익명 클래스에서 this는 익명 클래스 자신을 가르키지만 람다에서 this는 람다를 감싸는 클래스를 가르킨다.
- 익명 내부 클래스는 새로운 클래스파일이 생성되지만 람다는 static상관 없이 메서드로 생성이된다.
쉽게 메서드를 만드는 람다는 클래스를 만드는 것이 아니고 람다를 감싸는 클래스를 가리킨다.
public static void study(Supplier supplier){
System.out.println(supplier.getClass());
System.out.println(supplier.getClass().isAnonymousClass());
System.out.println("===========");
}
public static void main(String[] args) {
study(()-> 10);
study(new Supplier() {
@Override
public Object get() {
return 10;
}
});
}출력 ➡️ class 패키지명.클래스이름$$Lambda$시퀀스 번호..?
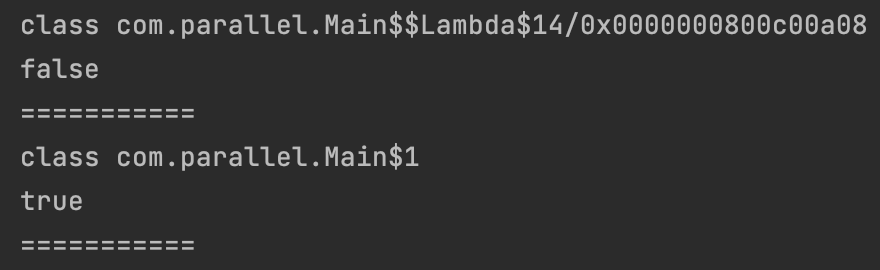
익명 클래스는 감싸고 있는 클래스의 변수를 가릴 수 있지만 람다 표현식을 가릴 수 없다.
- 익명 클래스에서 가리고 있는 클래스의 변수를 섀도 변수(shadow variable)이라고 한다.
public static void main(String[] args) {
int num = 20;
Runnable r1 = () -> {
int num = 10; // 컴파일 에러 발생
System.out.println(num);
};
new Runnable(){
@Override
public void run() {
int num = 10; // O
System.out.println(num);
}
};
}
클로저처럼 파라미터로 들어온 지역 변수가 아니라 멤버 변수를 이용하면 사용이 가능한거 같은데 아직 부족하지만 이해하기로는 Heap 영역에 할당 된 Object 타입의 참조를 위한 값들이 Stack 영역에 할당되기 때문에 캡처링 메커니즘을 이용하는 effectively final 특성을 가진 람다는 main함수에 있는 지역 변수에 값을 공유하여 사용되어 컴파일 에러가 발생하고 익명 클래스는 별도의 클래스 파일에 인스턴스 변수로 힙 영역에 생성되기 때문에 가능하다 정도로 이해했다.
헷갈리는 부분이 익명 클래스는 별도의 클래스이므로 해당 인스턴스는 변수를 포함해서 힙 영역에 생성이 되고, 람다식 내에서 사용하는 변수 또한 해당 메서드의 스택 프레임에 저장되는 것이 아니라 캡처되어 힙 영역에 저장되어 둘다 main함수의 스택프레임과 독립적으로 행동할 수 있을거 같다라는 점이었다.
저번에도 뭔가 조금은 이해했지만 이 주제에 대해서 java의 메모리 관리 JVM공부가 부족해 아직 따라가지 못하고 있다. 가까운 기간안에 공부해서 해결하도록 하겠다.
익명 클래스를 람다 표현식으로 바꾸면 콘텍스트 오버로딩에 따른 모호함이 초래될 수 있다.
익명 클래스는 인스턴스화할 때 명시적으로 형식이 정해지는 반면 람다의 형식은 콘텍스트에 따라 달라지기 때문이다.
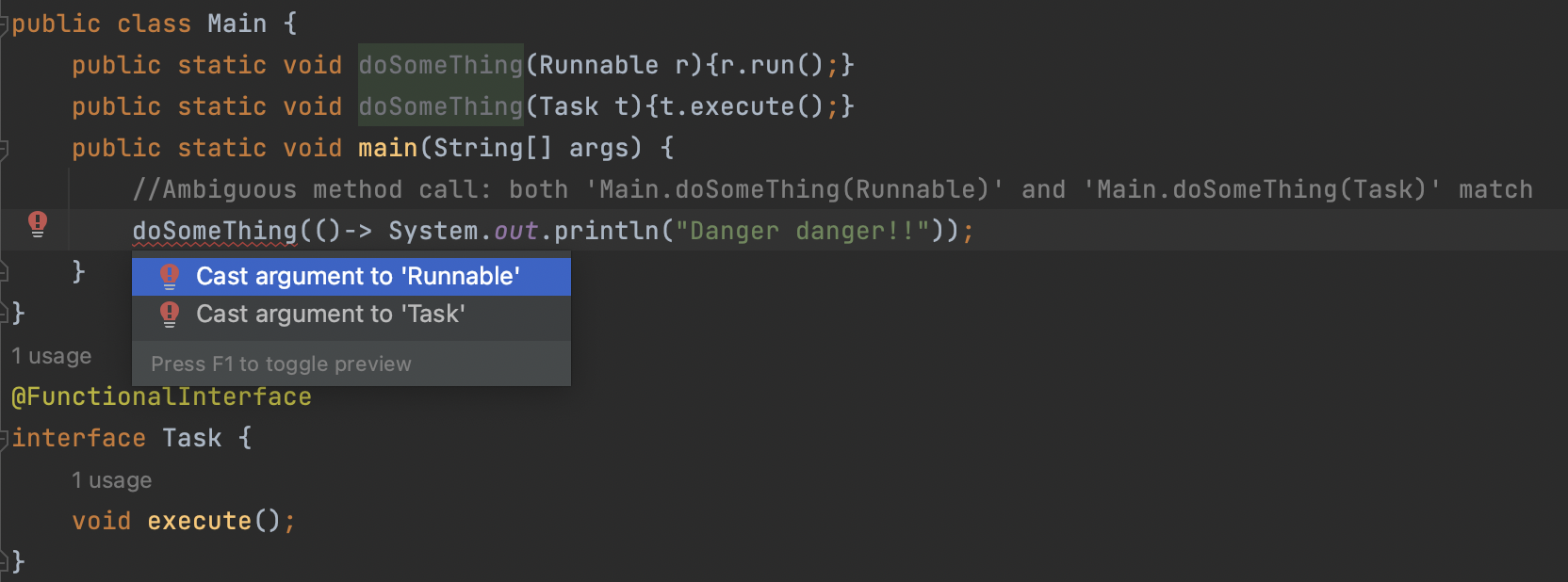
Intellij를 컴파일 에러가 발생하며 명시적 형변환을 지원해주기 때문에 모호함을 제거할 수 있다.
doSomeThing((Runnable) ()-> System.out.println("Danger danger!!"));
doSomeThing((Task) ()-> System.out.println("Danger danger!!"));
람다 표현식을 메서드 참조로 리팩터링하기
- 람다 표현식보다는 메서드 참조가 코드의 의도를 더 명확하게 보여준다.
menu.stream()
.collect(
groupingBy(dish -> {
if (dish.getCalories() <= 400) return CaloricLevel.DIET;
else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;
}));람다 표현식을 별도의 메서드로 추출한 다음에 groupongBy에 인수로 간결하게 전달할 수 있다.
public CaloricLevel getCaloricLevel(){
if (this.getCalories() <= 400) return CaloricLevel.DIET;
else if (this.getCalories() <= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;
}
//메서드 참조
menu.stream().collect(groupingBy(Dish::getCaloricLevel));comparing과 maxBy 같은 헬퍼 메서드는 메서드 참조와 조화를 이루도록 설계되어 있어 활용하기 좋다.
inventory.sort(
(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight()) //비교 구현에 신경써야 한다.
);
inventory.sort(comparing(Apple::getWeight)); //코드가 문제 자체를 설명한다.
sum,maximum등 자주 사용되는 리듀싱 연산은 메서드 참조와 함께 사용할 수 있는 내장 헬퍼 메서드를 제공한다.
Integer totalCalories = menu.stream().map(Dish::getCalories)
.reduce(0, (c1, c2) -> c1 + c2); //저수준 리듀싱 연산
Integer totalCalories = menu.stream().collect(summingInt(Dish::getCalories));//Collectors API저수준 리듀싱 연산을 조합하기 보다는 내장 컬렉터를 사용해 자신이 어떤 동작을 수행하는지 메서드 이름으로 이해할 수 있다.
명령형 데이터 처리를 스트림으로 리팩터링하기
반복자를 이용한 기존의 컬렉션 처리 코드를 스트림 API로 개선하자
- 쇼트서킷과 Lazy한 특성의 최적화
- 멀티코어 아키텍처 활용 가능성
- 데이터 처리 파이프라인의 명확성
//반복자 - 병렬 수행 어려움
List<String> dishNames = new ArrayList<>();
for (Dish dish: menu){
if (dish.getCalories() > 300){
dishNames.add(dish.getName());
}
}
//스트림
menu.stream().filter(dish -> dish.getCalories() > 300)
.map(Dish::getName)
.collect(toList());
명령형 코드의 break, continue, return 등의 제어 흐름문을 모두 분석해서 스트림 API로 바꾸기 힘들다. (몇 가지 도움을 주는 도구 사용)
코드 유연성 개선
조건부 연기 실행
보안 검사나 로깅 관련 메시지를 로깅하기 전에 logger 객체가 적절한 수준으로 설정되었는지 내부적으로 확인하는 log 메서드를 사용하는 것이 바람직하다.
- if문을 제거할 수 있으며 logger의 상태를 노출할 필요도 없어 바람직하다.
if (logger.isLoggable(Level.FINER)) {
logger.finer("Problem: "+ generateDiagnostic());
}
logger.log(Level.FINER, "Problem: "+ generateDiagnostic());특정 조건에서만 메시지가 생성될 수 있도록 메시지 생성 과정을 연기(defer)할 수 있어야 한다.
- java 8에서 Supplier를 인수로 갖는 오버로드된 log 메서드를 제공한다.
//log 메서드의 내부 구현 코드
public void log(Level level, Supplier<String> msgSupplier) {
if (!isLoggable(level)) {
return;
}
LogRecord lr = new LogRecord(level, msgSupplier.get()); //문자열 생성자에 넣어주고
doLog(lr); //람다 실행
}
//Supplier 사용하기
logger.log(Level.FINER,()->"Problem: "+ generateDiagnostic());- log 메서드는 logger의 수준이 적절하게 설정되어 있을 때만 인수로 넘겨진 람다를 내부적으로 실행한다.
클라이언트 코드에서 logger의 상태, 메시지 로깅등을 자주 확인할 때 내부적으로 객체의 상태를 확인한 다음 람다나 메서드 참조를 인수로 사용해서 메서드를 구현하는 것이 좋다. -아직 잘 이해되지 않으니 공부하기-
- 코드 가독성과 강화된 캡슐화를 통해 객체 상태가 클라이언트 코드로 노출되지 않는다.
실행 어라운드
매번 같은 준비, 종료 과정을 처리하는 로직을 람다를 통해서 다양한 방식으로 파라미터화 할 수 있다.
public class File {
public static String processFile(BufferedReaderProcessor p) throws IOException {
try (BufferedReader br = new BufferedReader(new FileReader("data.txt"))){
return p.process(br);
}
}
public static void main(String[] args) throws IOException {
String oneLine = File.processFile(br -> br.readLine());
String twoLine = File.processFile(br -> br.readLine() + br.readLine());
}
}
@FunctionalInterface
interface BufferedReaderProcessor {
String process(BufferedReader br) throws IOException;
}람다로 객체지향 디자인 패턴 리팩터링하기
람다 표현식으로 기존의 많은 객체지향 디자인 패턴을 제거하거나 간결하게 재구현할 수 있다.
전략(strategy) 패턴
한 유형의 알고리즘을 보유한 상태에서 런타임에 적절한 알고리즘을 선택하는 기법
- 다양한 기준을 갖는 입력값을 검증하기, 다양한 파싱 방법 사용하기, 입력 형식을 설정하기등
소문자 또는 숫자로 이루어져야 하는 등 텍스트 입력이 다양한 조건에 맞게 포맷되어 있는지 검증하기
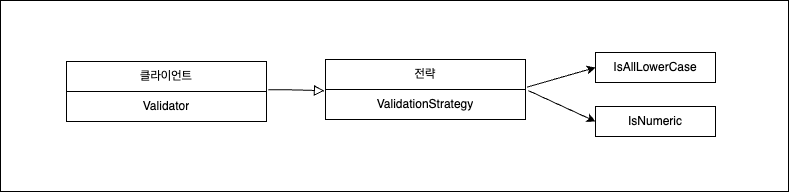
- 알고리즘을 나타내는 인터페이스 (Strategy 인터페이스)
- 다양한 알고리즘을 나타내는 한 개 이상의 인터페이스 구현체(IsAllLowerCase, IsNumeric)
- 전략 객체를 사용하는 한 개 이상의 클라이언트 Validator를 사용하는 main함수
interface ValidationStrategy {
boolean execute(String s);
}
class IsAllLowerCase implements ValidationStrategy {
@Override
public boolean execute(String s) {
return s.matches("[a-z]+");
}
}
class IsNumeric implements ValidationStrategy {
@Override
public boolean execute(String s) {
return s.matches("\\d+");
}
}
class Validator {
private final ValidationStrategy strategy;
public Validator(ValidationStrategy strategy) {
this.strategy = strategy;
}
public boolean validation(String s){
return strategy.execute(s);
}
}출력
public static void main(String[] args) {
Validator numericValidator = new Validator(new IsNumeric());
boolean b1 = numericValidator.validation("aaaa"); //true
Validator lowerCaseValidator = new Validator(new IsAllLowerCase());
boolean b2 = lowerCaseValidator.validation("bbbb"); //false
}람다 표현식 사용
ValidationStrategy는 함수형 인터페이스이며 Predicate<Strategy>과 같은 함수 디스크림터를 갖고 있다.
- 다양한 전략을 구현하는 새로운 클래스없이 람다 표현식을 직접 전달하면 코드가 간결해진다.
Validator numericValidator = new Validator((String s)->s.matches("[a-z]+"));
boolean b1 = numericValidator.validation("aaaa"); //true
Validator lowerCaseValidator = new Validator((String s)->s.matches("\\d+"));
boolean b2 = lowerCaseValidator.validation("bbbb"); //false
템플릿 메서드 패턴
알고리즘의 개요를 제시한 다음에 알고리즘의 일부를 고칠 수 있는 유연함을 제공해야 할 때 사용한다.
사용자가 고객ID를 입력하면 은행 DB에서 고객 정보를 가져오고 고객이 원하는 서비스를 제공할 수 있는 어플리케이션
- 은행마다 다양한 온라인 뱅킹 application을 사용하며 동작 방법도 다르다.
abstract class OnlineBanking {
public void processCustomer(int id) {
Customer c = Database.getCustomerWithId(id);
makeCustomerHappy(c);
}
abstract void makeCustomerHappy(Customer c);
}- processCustomer()는 온라인 뱅킹 알고리즘이 해야 할 일을 보여준다.
- 각각의 지점은 OnlineBanking 클래스를 상속받아서 makeCustomerHappy 메서드가 원하는 동작을 수행하도록 구현할 수 있다.
람다 표현식 사용
makeCusomerHappy()의 메서드 시그니처와 일치하도록 Consumer<Customer> 형식을 갖는 두 번째 인수를 processCustomer에 추가한다.
public void processCustomer(int id, Consumer<Customer> makeCustomerHappy) {
Customer c = Database.getCustomerWithId(id);
makeCustomerHappy.accept(c); //Consumer 함수형 인터페이스 사용
}OnlineBanking 클래스를 상속받지 않고 직접 람다 표현식을 전달해서 다양한 동작을 추가할 수 있다.
new OnlineBankingLambda().processCustomer(1337, (Customer c) -> System.out.println("Hello " + c.getName()));옵저버 패턴
어떤 이벤트가 발생했을 때 주제(subject)라고 불리는 한 객체가 옵저버(observer)라 불리는 다른 객체 리스트에 자동으로 알림을 보내야 하는 상황에서 사용한다.
- GUI 말고도 주식의 가격(주제) 변동에 반응하는 다수의 거래자(옵저버) 알림등 다양하게 사용할 수 있다.
다양한 신문 매체가 뉴스 트윗을 구독하고 있으며 특정 키워드를 포함하는 트윗이 등록되면 알림을 받고 싶은 경우

다양한 옵저버를 그룹화할 인터페이스
- 새로운 트윗이 있을 때 주제(Feed)가 호출할 수 있도록 notify라고 하는 하나의 메서드를 제공한다.
interface Observer {
void notify(String tweet);
}트윗에 포함된 다양한 키워드에 다른 동작을 수행할 수 있는 여러 옵저버를 정의할 수 있다.
class NYTimes implements Observer {
@Override
public void notify(String tweet) {
if (tweet != null && tweet.contains("money")) {
System.out.println("Breaking news in NY! "+tweet);
}
}
}
class Guardian implements Observer {
@Override
public void notify(String tweet) {
if (tweet != null && tweet.contains("queen")) {
System.out.println("yet more news from London... "+tweet);
}
}
}다양한 주제를 그룹화할 Subject 인터페이스
interface Subject {
void registerObserver(Observer o);
void notifyObservers(String tweet);
}주제는 registerObserver 메서드로 새로운 옵저버를 등록한 다음에 notifyObservers 메서드로 트윗의 옵저버에 이를 알린다.
- Feed는 트윗을 받았을 때 알림을 보낼 옵저버 리스트를 유지한다.
class Feed implements Subject {
private final List<Observer> observerList = new ArrayList<>();
@Override
public void registerObserver(Observer o) {
this.observerList.add(o);
}
@Override
public void notifyObservers(String tweet) {
observerList.forEach(o -> o.notify(tweet));
}
}
가디언도 우리의 트윗을 받아볼 수 있게 되었다.
public static void main(String[] args) {
Feed feed = new Feed();
feed.registerObserver(new NYTimes());
feed.registerObserver(new Guardian());
feed.notifyObservers("The queen said her favourite book is Modern Java in Action!");
}람다 표현식 사용하기
Observer 인터페이스를 구현하는 모든 옵저버 클래스는 트윗이 도착했을 때 어떤 동작을 수행할 것인지 감싸는 notify를 구현했다.
- 옵저버를 명시적으로 인스턴스화하지 않고 람다 표현식을 직접 전달해서 실행할 동작을 지정할 수 있다.
- 옵저버가 상태를 가지며, 여러 메서드를 정의하는 등 복잡하다면 람다 표현식보다 기존의 클래스 구현방식이 더 바람직할 수 있다.
public static void main(String[] args) {
Feed feed = new Feed();
feed.registerObserver((String tweet) -> {
processTweetWithPattern(tweet, "money", "Breaking news in NY! ");
});
feed.registerObserver((String tweet) -> {
processTweetWithPattern(tweet, "queen", "yet more news from London... ");
});
feed.notifyObservers("The queen said her favourite book is Modern Java in Action!");
}
private static void processTweetWithPattern(String tweet, String patternToSearch, String additionalInfo) {
if (tweet != null && tweet.contains(patternToSearch)) {
System.out.println(additionalInfo + tweet);
}
}
의무 체인 패턴
파이프라인처럼 작업 처리 객체의 체인(동작 체인 등)을 만들고 싶을 때 사용한다.
- 다음으로 처리할 객체 정보를 유지하는 필드를 포함하는 작업 처리 추상 클래스로 의무 체인 패턴을 구성한다.
- 작업 처리 객체가 자신의 작업을 끝냈으면 다음 작업 처리 객체로 결과를 전달한다.
작업 처리 객체
abstract class ProcessingObject<T> {
protected ProcessingObject<T> successor;
public void setSuccessor(ProcessingObject<T> successor) {
this.successor = successor; //다음 작업 객체 정보 유지
}
public T handle (T input){
T r = handleWork(input); // 현제 작업 객체 업무 수행
if (successor != null) return successor.handle(r); //다음 처리 객체 업무 수행후 반환
return r;
}
abstract protected T handleWork(T input);
}ProcessingObject 클래스를 상속받아 handleWork() 추상메서드를 구현하여 다양한 종류의 작업처리 객체를 만들 수 있다.
- 텍스트를 처리하는 예제
class HeaderTextProcessing extends ProcessingObject<String> {
@Override
protected String handleWork(String text) {
return "From Raoul, Mario and Alan: " + text;
}
}
class SpellCheckerProcessing extends ProcessingObject<String> {
@Override
protected String handleWork(String text) {
return text.replaceAll("labda", "lambda");
}
}두 작업 처리 객체를 연결해서 작업 체인을 만들 수 있다.
public static void main(String[] args) {
HeaderTextProcessing p1 = new HeaderTextProcessing();
SpellCheckerProcessing p2 = new SpellCheckerProcessing();
p1.setSuccessor(p2); //두 작업 처리 객체를 연결
String result = p1.handle("Aren't labdas really sexy?!!");
System.out.println(result);
}람다 표현식
이 패턴은 함수 체인(함수 조합)과 비슷하며 Function<String,String> 작업 처리 객체 형식의 인스턴스로 표현할 수 있다.
- 정확히 표현하면 UnaryOperator<String> 형식의 인스턴스로 표현할 수 있다.
- UnaryOperator<T>는 Function<T, T>를 상속 하고 있기 때문에 andThen 메서드로 이들 함수를 조합해서 체인을 만들 수 있다.
public static void main(String[] args) {
UnaryOperator<String> headerProcessing =
(String text) -> "From Raoul, Mario and Alan: " + text;
UnaryOperator<String> spellCheckerProcessing =
(String text) -> text.replaceAll("labda", "lambda");
Function<String, String> pipeline =
headerProcessing.andThen(spellCheckerProcessing); //동작 체인으로 두 함수 조합
String result = pipeline.apply("Aren't labdas really sexy?!!");
System.out.println(result);
}팩토리 패턴
인스턴스화 로직을 클라이언트에 노출하지 않고 객체를 만들 때 팩토리 디자인 패턴을 사용한다.
다양한 상품을 만드는 Factory 클래스
- 은행에서 일하고 있는데 은행에서 취급한는 대출, 채권, 주식 등 다양한 상품을 만들어야 한다고 가정
- createProduct() 메서드는 생산된 상품을 설정하는 로직을 포함할 수 있다.
class ProductFactory {
public static Product createProduct(String name){
switch(name) {
case "loan" : return new Loan();
case "stock" : return new Stock();
case "bond" : return new Bond();
default: throw new RuntimeException("No such product "+name);
}
}
}
//더미 데이터
interface Product{}
class Loan implements Product{}
class Stock implements Product{}
class Bond implements Product{}Lone, Stock, Bond는 모두 Product의 서브형식이다.
- 생성자와 설정을 외부로 노출하지 않음으로써 클라이언트가 단순하게 상품을 생산할 수 있다.
public static void main(String[] args) {
Product p = ProductFactory.createProduct("loan");
System.out.println(p instanceof Loan); //true
}람다 표현식 사용
생성자도 메서드 참조처럼 접근할 수 있어 상품명을 생성자로 연결하는 Map을 만들어서 코드를 재구현할 수 있다.
final static Map<String, Supplier<Product>> map = new HashMap<>();
static {
map.put("loan", Loan::new);
map.put("stock", Stock::new);
map.put("bond", Bond::new);
}
public static Product createProduct(String name){
Supplier<Product> p = map.get(name);
if (p != null) return p.get();
throw new IllegalArgumentException("No such product " + name);
}생성자가 여러 인수를 전달하는 상황에서는 Supplier 말고 TriFunction이라는 특별한 함수형 인터페이스 만들어 해결할 수 있지만 Map의 시그니처가 복잡해진다.
@FunctionalInterface
interface TriFunction<T, U, V, R> {
R apply(T t, U u, V v);
}
class ProductFactory {
final static Map<String, TriFunction<Integer, Integer, String, Product>> map = new HashMap<>();
static {
map.put("loan", Loan::new);
map.put("stock", Stock::new);
map.put("bond", Bond::new);
}
public static Product createProduct(String name, Integer arg1, Integer arg2, String arg3){
TriFunction<Integer, Integer, String, Product> f = map.get(name);
if (f != null) return f.apply(arg1,arg2,arg3);
throw new IllegalArgumentException("No such product " + name);
}
}람다 테스팅
개발자의 최종 업무는 제대로 작동하는 코드를 구현하는 것이지 깔끔한 코드를 구현하는 것이 아니다.
- 의도대로 동작하는지 확인할 수 있는 단위 테스팅(unit testing)을 해보자
//그래픽 애플리케이션의 일부 Point클래스
class Point {
private int x;
private int y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
public int getX() { return x; }
public int getY() { return y; }
public Point moveRightBy (int x){
return new Point(this.x + x, this.y);
}
}
//moveRightBy 메서드가 의도한 대로 동작하는지 확인하는 단위 테스트
@Test
@DisplayName("입력 받은 값만큼 x좌표를 이동할 수 있다.")
public void moveRightBy() {
//given
Point p1 = new Point(5,5);
//when
Point p2 = p1.moveRightBy(10);
//then
Assertions.assertEquals(15, p2.getX());
Assertions.assertEquals(5, p2.getY());
}보이는 람다 표현식의 동작 테스팅
람다를 익명클래스처럼 작성하면 따로 테스트할 수 없다.
- 필요하다면 람다를 필드에 저장해서 재사용할 수 있고 테스트할 수 있다.
class Point {
public final static Comparator<Point> compareByXAndThenY =
Comparator.comparing(Point::getX).thenComparing(Point::getY);
...
}람다 표현식은 함수형 인터페이스의 인스턴스를 생성하기 때문에 생성된 인스턴스의 동작으로 람다 표현식을 테스트할 수 있다.
@Test
@DisplayName("x좌표 기준으로 정렬하고 같다면 y좌표를 기준으로 정렬할 수 있다.")
public void testComparingTwoPoints() {
// given
Point p1 = new Point(5,5);
Point p2 = new Point(5,15);
// when
int result = Point.compareByXAndThenY.compare(p1, p2);
// then
Assertions.assertEquals(-1,result); //p1이 p2보다 y값이 작기 때문에 -1출력
}람다를 사용하는 메서드의 동작에 집중하라
람다의 목표는 정해진 동작을 다른 메서드에서 사용할 수 있도록 하나의 조각으로 캡슐화하는 것이다.
- 세부 구현을 포함하는 람다 표현식을 공개하면 안된다.
public static List<Point> moveAllPointsRightBy(List<Point> points, int x){
return points.stream()
.map(p -> new Point(p.getX() + x, p.getY()))
.collect(Collectors.toList());
}
람다 표현식을 사용하는 메서드의 동작을 테스트함으로써 람다를 공개하지 않으면서도 람다 표현식을 검증할 수 있다.
- moveAllPointsRightBy() 메서드의 람다 표현식인 p -> new Point(p.getX() + x, p.getY());를 테스트하는 부분이 없다.
@Test
@DisplayName("List에 담겨있는 모든 요소의 x좌표를 이동할 수 있다.")
public void testMoveAllPointsRightBy() {
// given
List<Point> points = List.of(new Point(5, 5), new Point(10, 5));
List<Point> expectedPoint = List.of(new Point(15,5), new Point(20, 5));
// when
List<Point> newPoints = Point.moveAllPointsRightBy(points, 10);
// then
Assertions.assertEquals(newPoints,expectedPoint);
}- 단위 테스트에서 보여주는 것처럼 Point 클래스의 equals 메서드는 중요한 메서드이기 때문에 Obejct의 기본적인 equals 구현을 그대로 사용하지 않으려면 equals 메서드를 적절하게 구현해야 한다.
복잡한 람다를 개별 메서드로 분할하기
람다 표현식을 메서드 참조로 리팩터링하여 일반 메서드를 테스트하듯이 람다 표현식을 테스트할 수 있다.
public CaloricLevel getCaloricLevel(){
if (this.getCalories() <= 400) return CaloricLevel.DIET;
else if (this.getCalories() <= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;
}
//메서드 참조
menu.stream().collect(groupingBy(Dish::getCaloricLevel));고차원 함수 테스팅
함수를 인수로 받거나 다른 함수를 반환하는 메서드를 고차원 함수(higher-order function)라고 한다.
- 메서드가 람다를 인수로 받는다면 다른 람다로 메서드의 동작을 테스트할 수 있다.
@Test
@DisplayName("메서드가 람다를 인수로 받는다면 다른 람다로 메서드의 동작을 테스트할 수 있다.")
public void testFilter() {
// given
List<Integer> numbers = Arrays.asList(1, 2, 3, 4);
// when
List<Integer> even = filter(numbers, i -> i % 2 == 0);
List<Integer> smallerThanThree = filter(numbers, i -> i < 3);
// then
Assertions.assertEquals(Arrays.asList(2,4), even);
Assertions.assertEquals(Arrays.asList(1,2), smallerThanThree);
}
public static <T> List<T> filter(List<T> list, Predicate<T> p){
ArrayList<T> result = new ArrayList<>();
for (T e: list){
if (p.test(e)) result.add(e);
}
return result;
}테스트해야 할 메서드가 다른 함수를 반환할 경우 보이는 람다 표현식의 동작 테스팅에서 살펴 본것처럼 함수형 인터페이스의 인스턴스로 간주하고 함수의 동작을 테스트할 수 있다.
디버깅
문제가 발생한 코드를 디버깅할 때 개발자가 가장 먼저 확인해야 하는 두가지!!
- 스택 트레이스
- 로깅
람다 표현식과 스트림은 기존의 디버깅 기법을 무력화한다.
스택 트레이스 확인
스택 프레임(stack frame)에서 예외 발생으로 프로그램 실행이 갑자기 중단되었을 때 어디에서 멈췄고 어떻게 멈추게 되었는지 정보를 얻을 수 있다.
- 프로그램에서이 메서드를 호출할 때 마다 프로그램에서의 호출 위치, 호출할 때의 인수값, 호출된 메서드의 지역 변수등의 호출 정보가 스택 프레임에 저장된다.
- 프레임 별로 문제가 발생한 지점에 이르게 된 메서드 호출 리스트(스택 트레이스)를 얻을 수 있다.
람다와 스택 트레이스
람다 표현식은 이름이 없기 때문에 조금 복작한 트레이스가 생성된다.
// 고의적으로 문제를 일으키도록 구현한 코드
public static void main(String[] args) {
List<Point> points = Arrays.asList(new Point(12, 2), null);
points.stream().map(p -> p.getX()).forEach(System.out::println); //NPE
}forEach메서드를 호출하면서 리스트 안에서 처음에 생성자를 통해서 넣은 Point는 출력되고 이 후 null값에서 x값을 얻어오려다가 예외가 발생했다.
- 스트림 파이프라인에서 에러가 발생했으므로 스트림 파이프라인 작업과 관련된 전체 메서드 호출 리스트가 출력되었다.
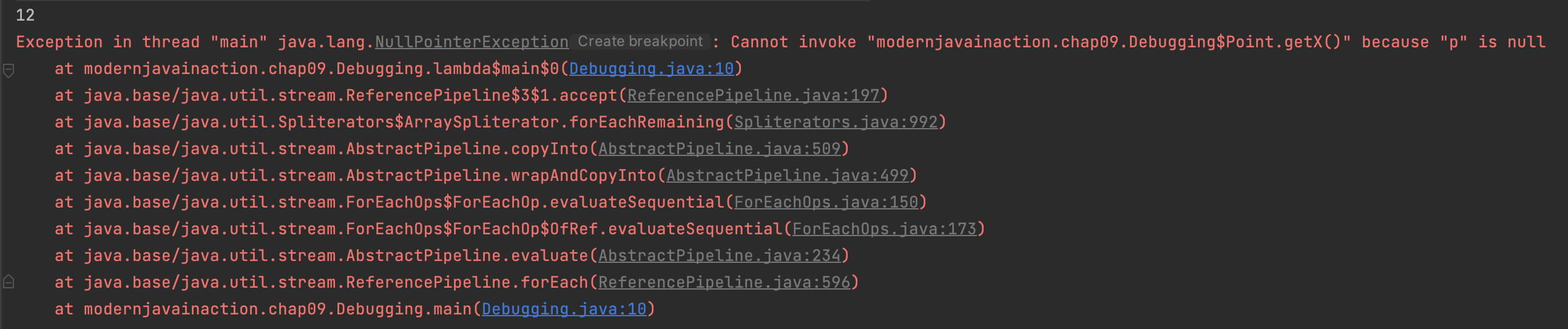
람다 표현식은 이름이 없으므로 컴파일러가 람다를 참조하는 이름을 lambda$main$0 만들었다.
- 클래스에 여러 람다 표현식이 있을 때는 이해하기 어렵다.
- 람다 표현식과 관련한 스택 트레이스는 이해하기 어려울 수 있다는 점을 염두하자
at modernjavainaction.chap09.Debugging.lambda$main$0(Debugging.java:10)
at java.base/java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:197)
메서드 참조를 사용하는 클래스와 같은 곳에 선언되어 있는 메서드를 참조할 때는 메서드 참조 이름이 스택 트레이스에 나타난다.
- p -> p.getX()를 메서드 참조 Point::getX로 고쳐도 스택 트레이스에는 메서드명이 나타나지 않는다.
public class Debugging {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3);
numbers.stream().map(Debugging::divideByZero)
.forEach(System.out::println);
}
public static int divideByZero(int n){
return n / 0;
}
}divideByZero 메서드는 스택 트레이스에 제대로 표시된다.
Exception in thread "main" java.lang.ArithmeticException: / by zero
at modernjavainaction.chap09.Debugging.divideByZero(Debugging.java:14)
at java.base/java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:197)
at java.base/java.util.Spliterators$ArraySpliterator.forEachRemaining(Spliterators.java:992)
...
정보 로깅
스트림의 파이프라인 연산을 디버깅할 때 forEach로 스트림 결과를 출력하거나 로깅할 수 있다.
List<Integer> numbers = Arrays.asList(2,3,4,5);
numbers.stream()
.map(x -> x + 17)
.filter(x -> x % 2 == 0)
.limit(3)
.forEach(System.out::println); //20, 22- forEach를 호출하는 순간 전체 스트림이 소비된다.
Peek이라는 스트림 연산을 활용해 각각의 연산(map, filter, limit)이 어떤 결과를 도출하는지 확인할 수 있다.
- forEach처럼 실제로 스트림의 요소를 소비하지 않는다.
- 자신이 확인한 요소를 파이프라인의 다음 연산으로 그대로 전달한다.
스트림 파이프라인의 각 동작 전후의 중간값을 출력할 수 있다.
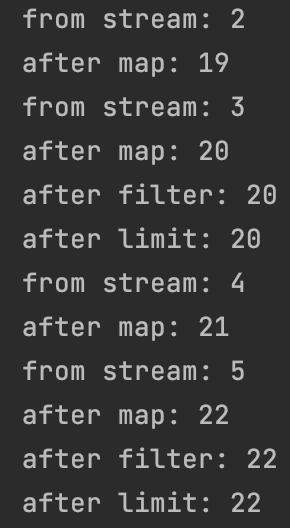
numbers.stream()
.peek(x -> System.out.println("from stream: " + x)) //소스에서 처음 소비한 요소 출력
.map(x -> x + 17)
.peek(x -> System.out.println("after map: " + x)) //map 동작 실행 결과 출력
.filter(x -> x % 2 == 0)
.peek(x -> System.out.println("after filter: " + x)) //filter 동작 후 선택된 숫자 출력
.limit(3)
.peek(x -> System.out.println("after limit: " + x)) //limit 동작 후 선택된 숫자 출력
.collect(Collectors.toList());출력
'책 > 모던 자바 인 액션' 카테고리의 다른 글
| 11. null 대신 optional 클래스 (0) | 2023.08.11 |
|---|---|
| 10. 람다를 이용한 도메인 전용 언어 (1) | 2023.08.04 |
| 8. 컬렉션 API 개선 (0) | 2023.07.28 |
| 7. 병렬 데이터 처리와 성능 (0) | 2023.07.26 |
| 6. 스트림으로 데이터 수집 (0) | 2023.07.21 |