
카프카 컨슈머: 개념
구독한 토픽들로부터 메시지를 받기 위해 KafkaConsumer를 사용하는데 해당 API 대해서 알아보기 전에 컨슈머와 컨슈머 그룹에 대해서 이해하자
컨슈머
애플리케이션은 컨슈머 객체(KafkaConsumer) 인스턴스를 생성하고 해당 토픽을 구독하면서 메시지를 받게된다.
- 컨슈머가 메시지를 읽는 속도보다 프로듀서가 더 빠르게 메시지를 쓰는 경우 처리가 계속 뒤로 밀리기 때문에 토픽으로부터 데이터를 읽어오는 작업을 확장할 수 있어야 한다.
컨슈머 그룹
동일한 컨슈머 그룹에 속한 여러 개의 컨슈머들이 동일한 토픽을 구독할 경우 각각의 컨슈머는 해당 토픽에서 서로 다른 파티션의 메시지를 받게된다.

컨슈머를 추가함으로써 단위 컨슈머가 처리하는 파티션과 메시지의 수를 분산시키는 규모 확장 방식이다.
- 토픽에 설정된 파티션 수 이상으로 컨슈머를 투입하면 컨슈머 중 몇몇은 유휴 상태가 되어 메시지를 전혀 받지 못한다.
- 토픽을 생성할 때 파티션 수를 크게 잡아주는게 좋은 이유 (확장 가능성)
Kafka의 주 디자인 목표 중 하나는 Kafka 토픽에 생성된 데이터를 전체 조직 안에서 여러 용도로 사용할 수 있도록 만드는 것이었습니다.
- 애플리케이션이 각자의 컨슈머 그룹을 갖도록 하면 성능 저하 없이 많은 수의 컨슈머와 컨슈머 그룹으로 확장할 수 있다.

- 토픽 T1에 들어있는 데이터는 G1과 G2가 각각 따로 수신하게 된다. G1이 수신했다고, G2가 수신하지 못하는 것이 아니다.
컨슈머 그룹과 파티션 리밸런스
컨슈머 그룹에 속한 컨슈머들은 자신들이 구독하는 토픽의 파티션들에 대한 소유권을 공유합니다.
새로운 컨슈머를 컨슈머 그룹에 추가하면 다른 컨슈머가 읽고 있던 파티션으로 부터 메시지를 읽기 시작합니다.
- 컨슈머가 종료되거나 크래시 났을 경우도 포함되며 토픽에 새 파티션을 추가했을 경우도 마찬가지다.
- 이렇게 컨슈머에 할당된 파티션을 다른 컨슈머에게 할당하는 작업을 리밸런스라고 한다.
컨슈머 그룹이 사용하는 파티션 할당 전략 2가지를 살펴보자
조급한 리밸런스(Eager Rebalance - 2.4 < 3.1 버전 기본값)
모든 컨슈머가 자신에게 할당된 파티션을 포기하고, 파티션을 포기한 컨슈머 모두가 다시 그룹에 참여한 뒤에야 새로운 파티션을 할당받고 읽기 작업을 재개할 수 있다.

- 전체 컨슈머 그룹에 대해 짧은 시간 동안 작업을 멈추게한다.
- 중단되는 시간은 컨슈머 그룹의 크기와 여러 설정 매개 변수에 영향을 받는다.
협력적 리밸런스(Cooperative Rebalance - 3.1 버전 이후 기본값)
한 컨슈머에게 할당되어 있던 파티션만을 다른 컨슈머에게 재할당하는 것을 의미합니다.
- 재할당되지 않은 파티션에서 레코드를 읽어서 처리하던 컨슈머들은 작업에 방해받지 않는다.
동작 과정
컨슈머 그룹 리더가 다른 컨슈머들에게 각자에게 할당된 파티션 중 일부가 재할당 된다고 통보
- 컨슈머들은 해당 파티션에서 데이터를 읽어 오는 작업을 멈추고 해당 파티션에 대한 소유권 포기
- 컨슈머 그룹 리더가 이 포기된 파티션들을 새로 할당

- 안정적으로 파티션이 할당될 때까지 몇 번 반복될 수 있으며 Eager Rebalance에서 발생하는 전체 작업이 중단되는 사태(stop the world)는 발생하지 않는다.
- 컨슈머 그룹의 그룹 코디네이터역할을 지정받은 카프카 브로커에 하트비트를 전송함으로써 생존확인을 진행한다.
파티션은 어떻게 컨슈머에게 할당될까?
컨슈머 그룹에 참여하고 싶을 때는 그룹 코디네이터에게 JoinGroup 요청을 보낸다.
- 가장 먼저 그룹에 참여한 컨슈머가 그룹 리더가 된다.
리더는 그룹 코디네이터로부터 해당 그룹 안에 있는 모든 컨슈머의 목록을 받아서 각 컨슈머에게 파티션의 일부를 할당한다.
(하트비트로 확인)
- 어느 파티션이 어느 컨슈머에게 할당되어야 하는지를 경정하기 위해서 PartitionAssignor 인터페이스 구현체가 사용된다.
파티션 할당이 결정되면 컨슈머 그룹 리더는 할당 내역을 그룹 코디네이터에게 전달하고 그룹 코디네이터는 다시 이 정보를 모든 컨슈머에게 전파한다.
- 각 컨슈머 입장에서는 자기에게 할당된 내역만 보인다.
- 리더만 클라이언트 프로세스 중에서 유일하게 그룹 내 컨슈머와 할당 내역 전부를 볼 수 있고 이 과정은 리밸런스가 발생할 때마다 반복적으로 수행된다.
정적 그룹 멤버십
컨슈머에 고유한 group.instance.id(컨슈머 그룹의 정적인 멤버가 되도록 해준다.) 값을 잡아주지 않으면 기본적으로, 컨슈머가 갖는 컨슈머 그룹의 멤버로서의 자격(멤버십)은 일시적이다.
- 컨슈머가 컨슈머 그룹을 떠나는 순간 해당 컨슈머에 할당되어 있는 파티션들은 해제
- 다시 참여하면 새로운 멤버 ID가 발급되면서 리밸런스 프로토콜에 의해 새로운 파티션들이 할당
컨슈머가 정적 멤버로 컨슈머 그룹에 참여하게 되는 경우
그룹 코디네이터는 그룹내 각 멤버에 대한 파티션 할당을 캐시해두고 있다.
- 정적 멤버가 다시 조인해 들어온다면 멤버십이 그대로 유지되기 때문에 리밸런스가 발생할 필요 없이 캐시되어 있는(예전에 할당받았던) 파티션들을 그대로 할당받는다.
- 같은 group.instance.id를 컨슈머가 같은 그룹에 조인할 경우 두 번째 컨슈머에는 동일한 ID를 갖는 컨슈머가 이미 존재한다는 에러가 발생
컨슈머 그룹의 정적 멤버는 종료할 때 미리 컨슈머 그룹을 떠나지 않고 session.timeout.ms 설정에 따라 해당 시간만큼 컨슈머가 응답이 없다면, 리밸런싱을 실행하게 된다.
- 리밸런스를 작동시키지 않을 만큼 충분히 크면서 설정한 시간 동안 작동이 멈출 경우 자동으로 파티션 재할당이 이루어져서 오랫동안 파티션 처리가 멈추는 상황을 막을 수 있을 만큼 충분히 작은 값으로 설정해야 한다.
정적 그룹 멤버십은 왜 사용하는 걸까?
각 컨슈머에 할당된 파티션의 내용물을 사용해서 로컬 상태나 캐시를 유지해야 할 때 편리하다.
- 캐시를 재생성하는 것이 시간이 오래 걸릴 때, 컨슈머가 재시작할 때마다 이 작업을 반복하는 것은 비효율적이다.
각 컨슈머에 할당된 파티션들이 해당 컨슈머가 재시작한다고 해서 다른 컨슈머로 재할당되지 않는다.
- 어떤 컨슈머도 재시작한 컨슈머에 잃어버린 파티션들로부터 메시지를 읽어오지 않기 때문이다.
- 정지되었던 컨슈머가 다시 돌아오면 이 파티션에 밀린 메시지부터 최신 메시지까지 처리하게 하면 된다.
- 재시작 했을 때 밀린 메시지들을 따라잡을 수 있는지 확인할 필요가 있다.
카프카 컨슈머 생성하기
KafkaProducer 인스턴스를 생성하는 것과 비슷하다.
- 필수값은 bootstrap.servers, key.deserializer, value.deserializer (역직렬화)
- 어떤 컨슈머 그룹에도 속하지 않는 컨슈머를 생성하는 것이 가능하지만(일반적이지 않음) 컨슈머 그룹을 지정하는 group.id 속성을 사용한다.
val props = Properties()
props[ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG] =
"borker 주소들 2개 이상 적어주는게 좋음"
props[ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG] =
"org.apache.kafka.common.serialization.StringDeserializer"
props[ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG] = "org.apache.kafka.common.serialization.StringDeserializer"
props[ConsumerConfig.GROUP_ID_CONFIG] =
"CountryCounter"
val consumer = KafkaConsumer<String, String>(props)
토픽 구독하기
컨슈머를 생성하고 나서 1개 이상의 토픽을 subscribe() 메서드로 구독하면 된다.
consumer.subscribe(listOf("topic1"))
- 토픽 목록을 매개변수로 받기 때문에 사용법이 간단하다.
정규식을 통해서 subscribe를 호출하는 것도 가능하다.
- 다수의 토픽 이름에 매치할 수 있는데 카프카와 다른 시스템 사이에 데이터를 복제하는 애플리케이션이나 스트림 처리 애플리케이션에서 흔하게 사용된다.
consumer.subscribe(Pattern.compile("test.*"))
- 정규식과 매치되는 이름을 가진 새로운 토픽을 생성할 경우 거의 즉시 리밸런스가 발생한다.
- 다수의 토픽에서 레코드를 읽어와서 토픽이 포함하는 서로 다른 유형의 데이터를 처리할 경우 편리하다.
정규식으로 토픽 구독 시 주의점
구독할 토픽을 필터링하는 작업은 클라이언트쪽에서 이루어지게 되므로 카프카 클러스터에 파티션이 매우 많다면 (3만개 이상이라든지) 주의해야 한다.
정규식으로 지정할 경우 컨슈머는 전체 토픽과 파티션에 대한 정보를 브로커에 일정한 간격으로 요청하게 된다.
- 구독할 토픽을 필터링하는 작업은 클라이언트 쪽에서 이루어지게 되는데 클라이언트는 이 목록을 구독할 새로운 토픽을 찾아내는 데 쓴다.
- 따라서 클라이언트는 클러스터 안에 있는 모든 토픽에 대한 상세 정보를 조회할 권한이 있어야 한다.
- 즉, 전체 클러스터에 대한 완전한 Describe 작업 권한이 부여되어야 한다.
토픽의 목록이 굉장히 크고, 컨슈머도 굉장히 많고, 토픽과 파티션의 목록 크기 역시 상당하다면 정규식을 사용한 구독은 브로커, 클라이언트, 네트워크 전체에 걸쳐서 상당한 오버헤드를 발생시킨다.
- 데이터를 주고받는 데 사용하는 네트워크 대역폭보다 토픽 메타데이터를 주고받는데 사용되는 대역폭 크기가 더 큰 경우도 있다.
폴링 루프
컨슈머 API의 핵심은 서버에 추가 데이터가 들어왔는지 폴링하는 단순한 루프다.
Duration timeout = Duration.ofMillis(100);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
log.info(
"topic: {}, partition: {}, offset: {}, customer: {}, country: {}",
record.topic(),
record.partition(),
record.offset(),
record.key(),
record.value());
int updatedCount = 1;
if (custCountryMap.containsKey(record.value())) {
updatedCount = custCountryMap.get(record.value()) + 1;
}
custCountryMap.put(record.value(), updatedCount);
JSONObject json = new JSONObject(custCountryMap);
log.info("json: {}", json);
}
}
- poll()에 전달하는 매개변수는 컨슈머 버퍼에 데이터가 없을 경우 블록될 수 있는 최대 시간을 결정한다.
- 값이 0이거나 버퍼 안에 이미 레코드가 준비되어 있을 경우 poll()은 즉시 리턴된다. 아닐 경우 지정된 ms 만큼 대기
새 컨슈머에서 처음으로 poll()을 호출하면 컨슈머는 GroupCoordinator를 찾아서 컨슈머 그룹에 참가하고, 파티션을 할당받는다.
- 리밸런스 역시 연관된 콜백들과 여기서 처리된다.
- 즉, 컨슈머 혹은 콜백에서 뭔가 잘못될 수 있는 거의 모든 것들은 poll()에서 예외의 형태로 발생
poll()이 max.poll.interval.ms에 지정된 시간 이상으로 호출되지 않을 경우, 컨슈머는 죽은 것으로 판정되어 컨슈머 그룹에서 퇴출된다.
- 폴링 루프 안에서 예측 불가능한 시간 동안 블록되는 작업을 수행하는 것은 피해야한다.
추가로 레코드를 읽어오지 않고 메타데이터만 가져오기 위해 이전 deprecated된 poll(0L)을 호출한다면
- 할당 받은 파티션에 대한 메타데이터를 받은 뒤, 하지만 레코드를 읽어오기 전 호출되는 rebalanceListener.onPartitionAssignment() 메서드에 로직을 위치시킬 수 있다.
스레드 안정성
하나의 스레드에서 동일한 그룹내에 여러개의 컨슈머를 생성할 수 없고, 같은 컨슈머를 다수의 스레드가 안전하게 사용할 수도 없다.
- 하나의 스레드당 하나의 컨슈머가 원칙이다.
하나의 애플리케이션에서 동일한 그룹에 속하는 여러개의 컨슈머를 운용하고 싶다면?
- 컨슈머 로직을 자체적인 객체로 감싼 다음 자바의 ExecutorService를 사용해서 각자의 컨슈머를 가지는 다수의 스레드를 시작하면 된다.
- 컨슈머 스레드는 1개만 실행하고 데이터 처리를 담당하는 워커 스레드(worker thread)를 여러 개 실행하는 방법 인 멀티 워커 스레드 전략
- 컨슈머 인스턴스에서 poll() 메서드를 호출하는 스레드를 여러 개 띄워서 사용하는 컨슈머 멀티 스레드 전략
컨슈머 멀티 워커 쓰레드 전략

KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);
consumer.subscribe(List.of("TOPIC_NAME"));
ExecutorService executorService = Executors.newCachedThreadPool();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(10));
for (ConsumerRecord<String, String> record : records) {
ConsumerWorker worker = new ConsumerWorker(record.value());
executorService.submit(worker);
}
}
멀티 스레드 사용시 주의점
자동 커밋(Autocommit)으로 인한 데이터 유실 위험
카프카 컨슈머에서 자동 커밋 설정이 활성화된 경우, 각 레코드가 완전히 처리되지 않았음에도 커밋이 발생할 수 있습니다.
- 리밸런싱이나 컨슈머 장애 발생 시, 아직 처리되지 않은 데이터를 커밋한 것으로 간주되어 데이터 유실로 이어질 수 있습니다.
각 레코드의 처리가 완료된 후에만 커밋을 수행함으로써 데이터 유실을 방지할 수 있습니다.
consumer.commitSync();
레코드 처리 순서의 역전(Out-of-Order) 현상
멀티 스레드 환경에서는 레코드가 순서대로 처리되지 않을 수 있습니다.
- 스레드를 생성하는 순서는 일정하더라도, 스레드 간의 처리시간이 다를 수 있기 때문이다.
역전 현상이 문제가 되지 않는 경우(로그 수집이나 모니터링 데이터 처리)에만 사용하거나 순서가 중요한 데이터 처리 경우 단일 스레드로 처리하거나 오더링 메커니즘을 도입해야 한다.
컨슈머 스레드 안정성
각 스레드에서 예외 상황이 발생하면 프로세스 전체가 종료될 위험이 있습니다.
- 개별 스레드에서 예외가 발생해도 다른 스레드에 영향을 주지 않도록 예외 처리를 철저히 설계해야 합니다
- 스레드별로 트랜잭션을 적용하거나, 예외를 처리하는 로직을 구현하여 안정성을 높일 수 있습니다.
컨슈머 설정하기
fetch.min.bytes(기본값 1byte)
컨슈머가 브로커로부터 레코드를 읽어올 때 데이터의 최소량 (byte 단위)을 지정할 수 있다.
- 이 설정값을 보고 메시지 양이 충분하지 않으면 대기합니다.
토픽에 새로운 메시지가 많이 들어오지 않거나 쓰기 요청이 적은 시간대와 같은 상황일 때 오가는 메시지 수를 줄임으로써 컨슈머와 브로커 양쪽에 대해 부하를 줄여준다.
- 읽어올 데이터가 그리 많지 않은 상황에서 컨슈머가 CPU 자원을 너무 많이 사용하고 있거나, 컨슈머 수가 많을 때 브로커의 부하를 줄여야 할 경우 fetch.min.bytes 를 기본값보다 올려주는 게 좋다.
- fetch.min.bytes 을 올려잡아 줄 경우 처리량이 적은 상황에서 지연도 증가하기 때문에 주의해야 한다.
fetch.max.wait.ms(기본값 500ms)
카프카가 컨슈머에게 응답하기 전 충분한 데이터가 모일 때까지 기다릴 수 있다.
- 해당 설정은 얼마나 오래 기다릴 것인지를 의미한다.
- 지연을 제한하고 싶다면 fetch.max.wait.ms 를 작게 잡아주면 된다.
fetch.max.wait.ms 가 100ms, fetch.min.bytes 가 1MB 일 경우 카프카는 컨슈머로부터 읽기 (fetch) 요청을 받았을 때 리턴할 데이터가 1MB 이상 모이거나 100ms 가 지나거나, 둘 중 하나가 만족하면 리턴하게 된다.
fetch.max.bytes(기본값 50MB)
브로커를 폴링할 때 반환하는 최대 바이트 수를 지정해 컨슈머가 서버로부터 받은 데이터를 저장하기 위해 사용하는 메모리의 양을 제한하기 위해 사용된다.
- 이 때 얼마나 많은 파티션으로부터 얼마나 많은 메시지를 받았는지와는 무관하다.
브로커가 컨슈머에 레코드를 보낼때는 배치 단위로 보내며, 만일 브로커가 보내야 하는 첫 번째 레코드 배치의 크기가 fetch.max.bytes 를 넘기면 fetch.max.bytes 의 제한값을 무시하고 해당 배치를 그대로 전송한다.
- 이 때 fetch.max.bytes에 설정된 bytes 만큼 잘라서 보내는게 아니며, 컨슈머가 읽기 작업을 계속해서 진행할 수 있도록 보장하기 위해서 전송하는 것이다.
대량의 데이터 요청은 대량의 디스크 읽기와 오랜 네트워크 전송 시간을 초래하여 브로커 부하를 증가시킬 수 있기 때문에 이를 막기 위해선 브로커 설정을 사용할 수 있다.
- 최대 읽기를 제한할 수 있는 브로커 설정: message.max.bytes
max.poll.records
poll() 을 호출할 때마다 리턴되는 최대 레코드 개수이다.
- 폴링 루프를 반복할 때마다 처리해야 하는 레코드의 개수를 제어할 때 사용한다.
max.partition.fetch.bytes (기본값 1MB)
서버가 파티션별로 리턴하는 최대 바이트 수를 결정한다.
KafkaConsumer.poll()이 ConsumerRecords를 리턴할 때 메모리상에 저장된 레코드 객체의 크기는 컨슈머에 할당된 파티션 별로 최대 max.partition.fetch.bytes 까지 차지할 수 있다.
브로커가 보내온 응답에 얼마나 많은 파티션이 포함되어 있는지 알 수 없기 때문에 max.partition.fetch.bytes 를 사용하여 메모리 사용량을 조절하는 것은 복잡하다.
- 각 파티션에서 비슷한 양의 데이터를 받아서 처리해야 하는 것과 같은 특별한 이유가 아니라면 fetch.max.bytes 설정을 대신 사용할 것을 강력히 권장한다.
session.timeout.ms 그리고 heartbeat.interval.ms
카프카가 처음 개발되던 온프레미스 데이터 센터를 기준으로 session.timeout.ms의 기본값으로 10s 정해졌다.
하지만 순간적인 부하 집중과 네트워크 불안정이 일상인 클라우드 환경에서 별것도 아닌 순간적인 네트워크 문제로 인해 리밸런스가 발생하고, 컨슈머 작동이 정지될 수 있었다.
10s 는 심지어 아래 나올 request.timeout.ms 의 기본값인 30s 와도 잘 맞지 않으며,
세션 타임아웃이 만료되어 이미 그룹에서 죽은 것으로 간주되었음에도 불구하고 계속해서 응답을 기다리는 상황이 발생할 수 있다.
- 카프카 3.0 버전 이전에는 session.timeout.ms 의 기본값은 10초였지만, 3.0 버전 이후부터는 45s 로 변경됨
컨슈머가 그룹 코디네이터에게 하트비트를 보내지 않은 채로 session.timeout.ms만큼 지나게 되면 컨슈머는 죽은 것으로 간주하고, 파티션 리밸런싱을 진행합니다.
- session.timeout.ms 를 낮게 잡을 경우
- 컨슈머 그룹이 죽은 컨슈머를 좀 더 빨리찾아내고 회복할 수 있도록 해주지만 그만큼 원치않은 리밸런싱을 초래할 수 있음
- session.timeout.ms 를 높게 잡을 경우
- 사고로 인한 리밸런스 가능성을 줄일 수 있지만, 실제로 죽은 컨슈머를 찾아내는 데 시간이 더 걸림
session.timeout.ms 는 컨슈머가 하트비트를 보내지 않을 수 있는 최대 시간을 결정하기 때문에 session.timeout.ms 와 heartbeat.interval.ms 는 보통 함께 변경된다.
- heartbeat.interval.ms는 하트비트를 몇초마다 보낼지를 의미합니다. (session.timeout.ms의 1/3 값으로 설정함)
max.poll.interval.ms (기본값 5분)
컨슈머가 폴링을 하지 않고도 죽은 것으로 판정되지 않을 수 있는 최대 시간으로 session.timeout.ms와 다르다.
하트비트와 세션 타임아웃은 카프카가 죽은 컨슈머를 찾아내고 할당된 파티션을 해제할 수 있게 해주는 주된 메커니즘이지만 하트비트는 백그라운드 스레드에 의해서 전송된다.
- 카프카에서 레코드를 읽어오는 메인 스레드는 데드락이 걸렸는데 백그라운드 스레드는 멀쩡히 하트비트를 전송하고 있을수도 있으며, 이는 컨슈머에 할당된 파티션의 레코들들이 처리되고 있지 않음을 의미한다.
max.poll.records 를 정의했다 할지라도 poll() 을 호출하는 시간 간격은 예측하기 어렵기 때문에 그에 대한 안전 장치로 max.poll.interval.ms 가 사용된다.
- max.poll.interval.ms 는 정상 작동 중인 컨슈머가 매우 드물게 도달할 수 있도록 충분히 크게, 하지만 정지한 컨슈머로 인한 영향이 뚜렷이 보이지 않을만큼 충분히 작게 설정해야 한다.
- max.poll.interval.ms 의 타임아웃이 발생하면 백그라운드 스레드는 브로커로 하여금 컨슈머가 죽어서 리밸런스가 수행되어야 한다는 것을 알 수 있도록 leave group 요청을 보낸 뒤 하트비트 전송을 중단한다.
default.api.timeout.ms (기본값 1분)
명시적으로 타임아웃을 지정하지 않는 한 거의 모든 컨슈머 API 호출에 적용되는 타임아웃 값이다.
- default.api.timeout.ms(기본값 1분)이 request.timeout.ms (기본값 30초)보다 크기 때문에 1분 안에 재시도 할 수 있다.
default.api.timeout.ms 이 적용되지 않은 중요한 예외로는 poll() 메서드가 있다.
- poll() 메서드는 호출할 때 언제나 명시적으로 타임아웃을 지정해줘야 한다.
request.timeout.ms (기본값 30s)
컨슈머가 브로커로부터 응답을 기다릴 수 있는 최대 시간이다.
브로커가 request.timeout.ms 에 설정된 시간 안에 응답하지 않을 경우 클라이언트는 브로커가 완전히 응답하지 않을 것으로 간주하여 연결을 닫은 뒤 재연결을 시도한다.
- 연결을 끊기 전 브로커에 요청을 처리할 시간을 충분히 주는 것이 중요하므로, request.timeout.ms 의 기본값인 30s 보다 더 내리지 않는 것을 권장한다.
이미 과부하에 걸려있는 브로커는 요청을 다시 보낸다고 얻을 게 거의 없을 뿐더러, 연결을 끊고 다시 맺는 것은 더 큰 오버헤드만 추가한다.
auto.offset.reset(기본값 latest)
컨슈머가 예전에 오프셋을 커밋한 적이 없거나, 커밋된 오프셋이 유효하지 않을 때 파티션의 메시지를 어디서 부터 읽어올지를 결정한다.
- 커밋된 오프셋이 유효하지 않은 경우는 보통 컨슈머가 오랫동안 읽은 적이 없어서 오프셋의 레코드가 이미 브로커에서 삭제된 경우
latest: 유효한 오프셋이 없을 경우 컨슈머는 가장 최신 레코드(컨슈머가 작동하기 시작한 다음부터 쓰여진 레코드)부터 읽기 시작함
earliest: 유효한 오프셋이 없을 경우 파티션의 맨 처음부터 모든 데이터를 읽음
none: 유효하지 않은 오프셋부터 읽으려 할 경우 예외 발생
enable.auto.commit(기본값 ture)
컨슈머가 자동으로 오프셋을 커밋할지를 결정한다.
- true 로 설정 시 auto.commit.interval.ms를 사용하여 얼마나 자주 오프셋이 커밋될지 제어할 수 있다.
- 언제 offset을 커밋할 지 직접 결정하고 싶거나 중복을 최소화하고 유실되는 데이터를 방지하려면 false로 설정해야 한다.
partition.assignment.strategy
파티션 할당 전략은 카프카 컨슈머가 구독하는 대상 토픽 중 어느 파티션의 레코드를 읽을 지 결정하는 방식이다.
- 컨슈머 그룹에 설정된 파티션 전략에 따라 컨슈머-파티션 간의 매칭이 결정되며 리밸런싱 시 발생하는 모든 동작은 컨슈머 리더가 처리한다.
PartitionAssinor 클래스는 컨슈머에게 이들이 구독한 토픽들이 주어졌을 때 어느 컨슈머에게 어느 파티션을 할당될지를 결정하는 역할을 한다.
카프카 2.4 부터 기본값은 org.apache.kafka.clients.consumer.CooperativeStickyAssinor 이다.
- 2.3 이하의 버전에서 업그레이드를 하고 있다면 Cooperative Sticky 할당 전략을 활성화하기 위해 특정한 업그레이드 순서를 따라야 한다.

- 사용자 정의를 위해서는 org.apache.kafka.clients.consumer.ConsumerPartitionAssignor 인터페이스를 구현하면 된다.
카프카가 제공하는 파티션 할당 전략
Range
컨슈머가 구독하는 각 토픽의 파티션들을 연속된 그룹으로 나눠서 할당한다.
- 컨슈머 C1, C2 가 각각 3개의 파티션을 갖는 토픽 T1, T2 를 구독할 경우 파티션 할당은 아래와 같이 이루어진다.

각 컨슈머가 받아야 할 파티션 수를 결정하는데, 이는 해당 토픽의 전체 파티션 수를 컨슈머 그룹의 총 컨슈머 수로 나눈 값이다.
- 따라서 컨슈머 수와 파티션 수가 균등하게 나눠지지 않을 경우 첫 번째 컨슈머는 두 번째 컨슈머보다 더 많은 파티션을 할당받게 된다. (Range 전략을 사용하면 언제든지 발생할 수 있다.)
- 컨슈머의 파티션 할당이 불균형하기 때문에 특정 컨슈머에 부하가 몰릴 수 있다.
조급한 리밸런싱으로 동작하므로 리밸런싱 발생시 모든 컨슈머가 작업을 중단하게 된다.
RoundRobin
모든 구독된 토픽의 모든 파티션을 순차적으로 하나씩 컨슈머에게 할당한다.
- 컨슈머 그룹 내 모든 컨슈머들이 동일한 토픽을 구독한다면 (실제로 보통 그렇다.) 모든 컨슈머들이 완전히 동일한 수 (혹은 많아야 1개 차이) 의 파티션을 할당받게 된다.
조급한 리밸런싱으로 동작하므로 리밸런싱 발생시 모든 컨슈머가 작업을 중단하게 된다.
- 모든 파티션을 균등하게 분배하려 하기 때문에 하나의 컨슈머만 다운되더라도 모든 컨슈머의 리밸런싱이 필요하다.
- Rebalancing시에도 토픽들의 파티션과 Consumer들을 균등하게 매핑하므로 Rebalance 이전의 파티션과 Consumer들의 매핑이 변경되기 쉽다.
Sticky
Stikcy 파티션 할당 전략은 리밸런싱이 발생하더라도 기존 매핑 정보를 최대한 유지하는 컨슈머-파티션 할당 전략이다.
Sticky 할당자의 목표 2가지
- 파티션들을 가능한 균등하게 할당하기 위해 RoundRobin 할당자를 사용하는 것과 유사하다.
- 리밸런스가 발생했을 때 가능하면 많은 파티션들이 같은 컨슈머에 할당되게 함으로써 할당된 파티션을 하나의 컨슈머에서 다른 컨슈머로 옮길 때 발생하는 오버헤드를 최소화한다.
Sticky 파티션 할당 전략이 이상적으로 동작하는 이유
- 컨슈머 간 최대 할당된 파티션 수의 차이는 1개
- 기존에 존재하는 파티션 할당은 최대한 유지
- 재할당 동작 시 휴요하지 않은 모든 파티션 할당은 제거
- 할당되지 않은 파티션들은 균형을 맞추는 방법으로 컨슈머들에게 할당

- 컨슈머 2 에 장애가 생겨 컨슈머 그룹에서 이탈하면 리밸런싱이 발생하게 되는데, 정상 동작하는 나머지 2개의 컨슈머의 매핑은 최대한 유지하고 매핑이 해제된 파티션만 재할당 된다.
- 매핑은 최대한 유지하지만 결국 조급한 리밸런싱으로 동작하기 때문에 리밸런싱 발생 시 Stop the world 현상이 발생한다.
같은 그룹에 속한 컨슈머들이 서로 다른 토픽을 구독할 경우 Sticky 할당자를 사용한 할당이 RoundRobin 할당자를 사용한 것보다 더 균형잡히게 된다.
- 라운드로빈 파티션 할당 전략은 정상동작하는 나머지 2개도 리밸런싱에 동참하게 되어 기존 파티션 매핑이 모두 해제되고 재할당된다.
Cooperative Sticky
Sticky 파티션 할당 전략과 결과적으로 동일하지만 컨슈머가 재할당되지 않은 파티션으로부터 레코드를 계속해서 읽어올 수 있도록 해주는 협력적 리밸런스 기능을 지원한다.
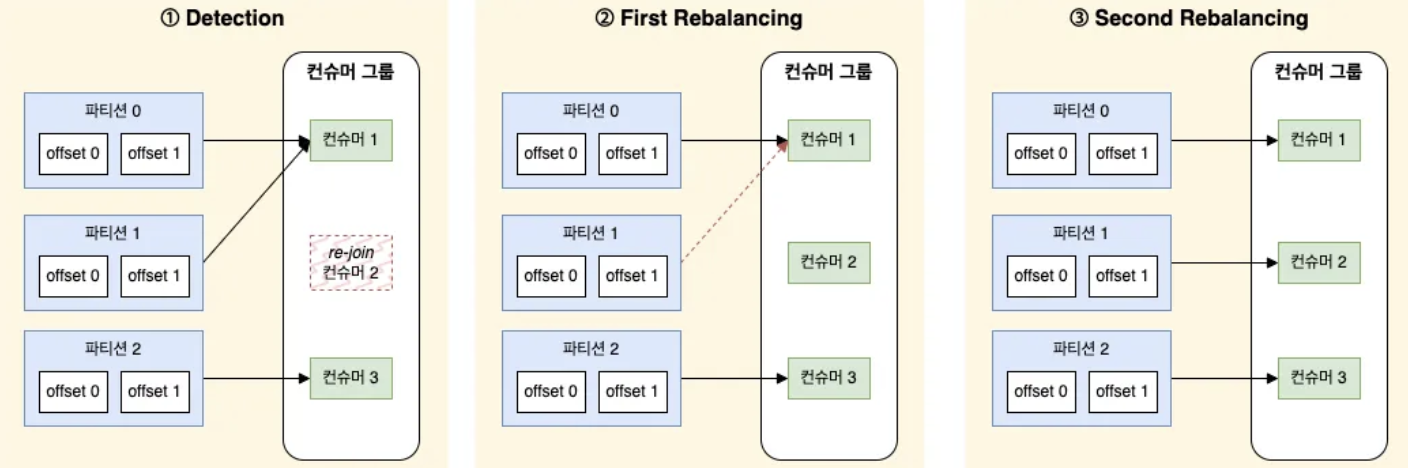
문제가 있는 파티션의 메시지 컨슈밍만 중단될 뿐 이 외의 파티션은 모두 정상적으로 메시지 컨슈밍이 동작하기 때문에 전체적인 데이터 처리 성능을 크게 저하하지 않는다.
- 컨슈머 그룹의 구성 변경이 자주 발생하는 환경에 특히 유용하며, 효율적인 리밸런싱을 수행할 수 있다.
client.id
어떠한 문자열도 될 수 있으며, 브로커가 요청 (읽기 요청 등) 을 보낸 클라이언트를 식별하기 위해 쓰인다.
- 로깅, 모니터링 지표, 쿼터에서도 사용
client.rack
컨슈머가 각 파티션의 리더로 레플리카로 부터 메시지를 읽어오는게 아니라 가장 가까운 replica 로부터 읽어올 수 있도록 제공하는 옵션이다.
- client.rack 설정을 잡아주어 클라이언트가 위치한 영역을 식별할 수 있게 해주면 된다.
- 그리고 나서 replica.selector.class 설정 기본값을 org.apache.kafka.common.replica.RackAwareReplicaSelector 로 잡아주면 된다.
읽어올 replica 를 선택하는 로직을 직접 구현하고 싶으면 ReplicaSelector 인터페이스를 구현하는 클래스를 구현한 뒤 replica.relector.class 가 그 클래스를 가리키게 하면 된다.
시간이 흐르면서 클라우드 환경에서 카프카를 작동시키는 것이 더 일반적이 되었고,
brocker.rack 설정 역시 물리적 서버 랙이라기 보다 클라우드의 가용 영역을 가리키는 경우가 많아지게 되었다.
브로커와 컨슈머가 같은 지역에 있더라도 다른 가용 영역에 있으면 실제로 위치한 데이터센터 역시 다를 가능성이 높은데,
이 때 자연히 네트워크 속도 또한 떨어질 수 밖에 없다.
group.instance.id
컨슈머에 정적 그룹 멤버십 기능을 적용하기 위해 사용되는 설정으로, 어떤 고유한 문자열도 사용 가능하다.
- 정적 그룹 멤버들끼리는 컨슈머가 꺼졌다 켜져도 같은 파티션을 할당받기에 리밸런싱이 일어나지 않는다.
receive.buffer.bytes, send.buffer.bytes
데이터를 읽거나 쓸 때 소켓이 사용하는 TCP 의 수신 및 송신 버퍼의 크기이다.
- -1은 기본 OS값을 의미하며 다른 데이터센터에 있는 브로커와 통신하는 프로듀서나 컨슈머의 경우 보통 지연이 크고 대역폭은 낮으므로 이 값을 올려 잡아주는 것이 좋다.
offsets.retention.minutes (기본값 7일)
브로커 설정이지만 컨슈머 작동에 큰 영향을 미친다.
컨슈머 그룹에 현재 돌아가고 있는 컨슈머들이 있는 한, 컨슈머 그룹이 각 파티션에 대해 커밋한 마지막 오프셋 값은 카프카에 의해 보존되기 때문에 재할당이 발생하거나 재시작을 한 경우에도 가져다 쓸 수 있다.
- 하지만 컨슈머 그룹이 비게 된다면 카프카는 커밋된 오프셋을 offsets.retention.minutes 에 설정된 기간동안만 보관한다.
커밋된 오프셋이 삭제된 상태에서 컨슈머 그룹이 다시 활동을 시작하면 과거에 수행했던 읽기 작업에 대한 기록이 전혀없는, 마치 완전히 새로운 컨슈머 그룹인 것처럼 동작한다.
오프셋과 커밋
poll()을 호출할 때마다 카프카에 쓰여진 메시지 중 컨슈머 그룹에 속한 컨슈머가 읽지 않은 메시지를 리턴합니다.
- JSM 큐들이 하는 것처럼 컨슈머로부터의 응답을 받는 방식이 아니기 때문에 그룹 내의 컨슈머가 어떤 레코드를 읽었는지 판단할 수 없다.
- 컨슈머가 카프카에 특수 토픽인 __consumer_offsets 토픽에 각 파티션별로 커밋된 오프셋을 업데이트하도록 메시지를 보내면서 파티션에서의 현재 위치를 업데이트하는 오프셋 커밋 작업이 이루어진다.
컨슈머가 크래시되거나 새로운 컨슈머가 그룹에 추가되어 리밸런스가 이루어질 때 각각의 컨슈머는 리밸런스 이전에 처리하고 있던 것과는 다른 파티션들을 할당받을 수 있다.
- 작업을 다시 재개하기 위해 컨슈머는 각 파티션의 마지막 커밋된 메시지를 읽어온 뒤 거기서 부터 처리한다.
커밋된 오프셋이 클라이언트가 처리한 마지막 메시지의 오프셋보다 작을 경우

- 마지막으로 처리된 오프셋과 커밋된 오프셋 사이의 메시지들은 두번 처리되게 된다.
커밋된 메시지가 클라이언트가 실제로 처리한 마지막 메시지의 오프셋보다 클 경우

- 마지막으로 처리된 오프셋과 커밋된 오프셋 사이의 모든 메시지들은 컨슈머 그룹에서 누락되게 된다.
오프셋을 커밋할 때 자동으로 커밋하건 오프셋을 지정하지 않고 하든 상관없이 poll() 이 리턴한 마지막 오프셋 바로 다음 오프셋을 커밋하는 것이 기본 동작이다.
- 수동으로 특정 오프셋을 커밋하거나 특정 오프셋 위치를 탐색(seek) 할 때 주의하자.
자동 커밋
enable.auto.commit 을 true 로 설정하면 컨슈머는 auto.commit.interval.ms 기본값인 5초에 한번 poll() 을 통해 받은 메시지 중 마지막 메시지의 오프셋을 커밋한다.
- 자동 커밋은 폴링 루프에 의해서 실행된다.
- poll() 메서드를 실행할 때마다 컨슈머는 커밋해야 하는지를 확인한 뒤 그러할 경우 마지막 poll() 호출에서 return된 offset을 commit 한다.
기본값 5초를 기준으로 마지막으로 커밋한 지 3초가 지난 뒤에 컨슈머가 크래시된다면 리밸런싱이 완료된 뒤부터 남은 컨슈머들은 크래시된 컨슈머가 읽고 있던 파티션들을 이어받아서 읽기 시작한다.
- 문제는 남은 컨슈머들이 마지막으로 커밋된 오프셋부터 작업을 시작하는데, 커밋되어 있는 오프셋은 3초 전의 것이기 때문에 크래시되기 3초 전까지 읽혔던 이벤트들이 중복 처리된다.
- 오프셋을 더 자주 커밋하여 레코드가 중복될 수 있는 윈도우를 줄어들도록 커밋 간격을 줄여서 설정할 수는 있지만 중복을 완전히 없애는 것을 불가능하다.
자동 커밋 기능이 켜진 상태에서 오프셋을 커밋할 때가 되면 다음 번에 호출된 poll() 이 이전 호출에서 리턴된 마지막 오프셋을 커밋한다.
- 이 동작은 어느 이벤트가 실제로 처리되었는지 알지 못하기 때문에 poll() 을 다시 호출하기 전 이전 호출에서 리턴된 모든 이벤트들을 처리하는 게 중요하다.
- 이것은 보통은 문제가 되지 않지만, 폴링 루프에서 예외를 처리하거나 루프를 일찍 벗어날 때 주의해야 한다.
자동 커밋은 편리하지만, 중복 메시지를 방지하기엔 충분하지 않다.
현재 오프셋 커밋하기
대부분의 개발자들은 메시지 유실의 가능성을 제거하고 리밸런스 발생 시 중복되는 메시지의 수를 줄이기 위해 오프셋이 커밋되는 시각을 제어하려 한다.
- enable.auto.commit 을 false 로 설정하고 가장 간단하고 신뢰성있는 커밋 API인 commitSync() 사용
- commitSync() 는 poll() 이 리턴한 마지막 오프셋을 커밋한 뒤 커밋이 성공적으로 완료되면 리턴, 실패하면 예외를 발생시킨다.
주의점
- poll() 에서 리턴된 모든 레코드의 처리가 완료되기 전에 commitSync() 를 호출하게 될 경우 애플리케이션이 크래시되었을 때 커밋은 되었지만 아직 처리되지 않은 메시지들이 누락될 수 있다.
- 애플리케이션이 아직 레코드들을 처리하는 도중에 크래시가 날 경우, 마지막 메시지 배치의 맨 앞 레코드부터 리밸런스 시작 시점까지의 모든 레코드들은 중복 처리된다. (메시지 유실보다 좋을지 고민하기)
가장 최근의 메시지 배치를 처리한 뒤 commitSync() 를 호출하여 오프셋을 커밋하는 예시
Duration timeout = Duration.ofMillis(100);
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props)) {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
log.info(
"topic: {}, partition: {}, offset: {}, customer: {}, country: {}",
record.topic(),
record.partition(),
record.offset(),
record.key(),
record.value());
}
try {
consumer.commitSync();
} catch (CommitFailedException e) {
log.error("commit failed: {}", e.getMessage());
}
}
}
비동기적 커밋
수동 커밋의 단점 중 하나는 브로커가 커밋 요청에 응답할 때까지 애플리케이션이 블록되어 처리량이 제한된다는 점이다.
- 커밋 수를 줄이면 처리량을 올라가겠지만 결국 자동 커밋과 동일하게 리밸런스에 의한 중복 메시지 수는 늘어난다.
- 비동기적 커밋 API인 commitAsync()를 사용하면 브로커가 커밋에 응답할 때까지 기다리는 대신 요청만 보내고 처리는 계속한다.
Duration timeout = Duration.ofMillis(100);
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props)) {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
log.info(
"topic: {}, partition: {}, offset: {}, customer: {}, country: {}",
record.topic(),
record.partition(),
record.offset(),
record.key(),
record.value());
}
// 마지막 오프셋을 커밋하고 처리 작업을 계속함
consumer.commitAsync();
}
}
commitSync() 는 성공하거나 재시도가 불가능한 실패가 발생할 때까지 재시도를 하지만, commitAsync() 는 재시도를 하지 않는다.
- commitAsync()가 일시적으로 실패한 앞 (오프셋 2000 커밋) 의 요청을 재시도해서 성공한다면 오프셋 3000 까지 처리되어 커밋이 완료된 후 다음 오프셋으로 2000이 커밋되는 상황이 발생할 수 있다.
commitAsync() 에 있는 브로커가 보낸 응답을 받았을 때 호출되는 콜백에서 재시도를 하기 위해 사용될 경우 커밋 순서 관련된 문제에 주의해야 한다.
consumer.commitAsync(
new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception e) {
if (e != null) {
log.error("Commit failed of offsets: {}", e.getMessage());
}
}
});
}
- 커밋 요청을 보낸 뒤 처리를 계속하는데 커밋이 실패할 경우, 실패가 났다는 사실과 함께 오프셋이 로그된다.
비동기적 커밋 재시도하기
auto-increment같은 번호를 사용해서 비동기적 커밋을 재시도할 때 순서를 맞출 수 있다.
- 커밋할 때마다 번호를 1씩 증가시킨 뒤 commitAsync 콜백에 해당 번호를 넣어준다.
- 재시도 요청을 보낼 준비가 되었을 때 콜백에 주어진 번호와 현재 번호를 비교한다.
- 콜백에 주어진 번호가 더 크다면 새로운 커밋이 없었다는 의미이므로 재시도를 해도 되지만 그게 아니라면 새로운 커밋이 있었기 때문에 재시도 하면 안된다.
동기적 커밋과 비동기적 커밋을 함께 사용하기
대체로 재시도 없는 커밋은 일시적인 문제일 경우 뒤이은 커밋이 성공할 것이기 때문에 크게 문제가 되지 않는다.
- 하지만 그 커밋이 컨슈머를 닫기 전 커밋이거나 리밸런스 전 마지막 커밋이라면 성공 여부를 추가로 확인할 필요가 있다.
- 이럴 때 일반적인 패턴은 종료 직전에 commitAsync() 와 commitSync() 를 함께 사용하는 것이다.
Duration timeout = Duration.ofMillis(100);
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props)) {
boolean closing = false; // TODO: closing 업데이트
while (!closing) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
log.info(
"topic: {}, partition: {}, offset: {}, customer: {}, country: {}",
record.topic(),
record.partition(),
record.offset(),
record.key(),
record.value());
}
// 정상적인 상황에서는 비동기 커밋 사용한다. 더 빠를 뿐더러 커밋이 실패해도 다음 커밋이 성공할 수 있음
consumer.commitAsync();
}
// 컨슈머를 닫는 상황에서는 '다음 커밋' 이 없으므로 commitSync() 를 호출하여 커밋의 성공하면 종료, 회복 불가능한 에러가 발생할 때까지 재시도함
consumer.commitSync();
} catch (Exception e) {
log.error("Unexpected error: {}", e.getMessage());
}
KafkaConsumer 클래스가 closeable을 구현함으로써 try-with-resources를 사용할 수 있다.


특정 오프셋 커밋하기
가장 최근 오프셋을 커밋하는 것은 메시지 배치 처리가 끝날 때만 수행이 가능하다.
poll() 이 엄청나게 큰 배치를 리턴했는데 리밸런스가 발생한 경우 전체 배치를 재처리하는 상황을 피하기 위해 배치를 처리하는 도중에 오프셋을 커밋하고 싶다면 어떻게 해야할까?
- commitSync() 와 commitAsync() 는 아직 처리하지 않은, 리턴된 마지막 오프셋을 커밋하기 때문에 이 경우엔 단순히 commitSync() 와 commitAsync() 를 호출할 수 없다.
컨슈머 API 에는 commitSync() 와 commitAsync() 호출 시 커밋하고자 하는 파티션과 오프셋의 map 을 전달할 수 있다.
- 레코드 배치 처리 중이고, customers 토픽의 파티션 3 에서 마지막으로 처리한 메시지의 오프셋이 5000 이라면 customers 토픽의 파티션 3 의 오프셋 5001 에 대한 commitSync() 를 호출해주면 된다.
- 컨슈머가 하나 이상의 파티션으로부터 레코드를 읽어오고 있을 경우, 모든 파티션의 오프셋을 추적해야 할 필요가 있기 때문에 코드가 복잡해질 것이다.
// 오프셋을 추적하기 위해 사용할 맵
Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();
int count = 0;
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
Duration timeout = Duration.ofMillis(100);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
log.info(
"topic: {}, partition: {}, offset: {}, customer: {}, country: {}",
record.topic(),
record.partition(),
record.offset(),
record.key(),
record.value());
// 각 레코드를 처리한 후 맵을 다음에 처리할 것으로 예상되는 오프셋으로 업데이트
currentOffsets.put(
new TopicPartition(record.topic(), record.partition()),
// 향후에 읽기 시작할 메시지의 위치 (마지막 오프셋 + 1)
new OffsetAndMetadata(record.offset() + 1, "no metadata"));
// 1000개의 레코드마다 현재 오프셋 커밋하는데, 실제 운영 시엔 시간 혹은 레코드의 내용을 기준으로 커밋해야 함
if (count % 1000 == 0) {
// commitSync() 도 사용 가능
consumer.commitAsync(currentOffsets, null); // 여기선 callback 을 null 로 처리
}
count++;
}
}
- 특정 오프셋을 커밋할 때는 모든 에러를 직접 처리해주어야 한다.
리밸런스 리스너
컨슈머는 종료하기 전이나 리밸런싱이 시작되기 전에 정리 작업 (cleanup)을 해주어야 한다.
- 컨슈머에 할당된 파티션이 해제될 것이라는 것을 알게 된다면 해당 파티션에서 마지막으로 처리한 이벤트의 오프셋을 커밋하고, 파일 핸들이나 DB 연결 등도 닫아주어야 한다.
컨슈머 API 는 파티션이 할당되거나 해제될 때 사용자의 코드가 실행되도록 해주는 메커니즘을 제공한다.
- subscribe() 를 호출할 때 ConsumerRebalanceListener 를 전달해주면 된다.

void onPartitionsRevoked(Collection<TopicPartition> partitions)
컨슈머가 할당받았던 파티션이 할당 해제될 때 호출됨 (리밸런스 때문일 수도 있고, 컨슈머가 닫혀서 그럴 수도 있다.)
- 여기서 오프셋을 커밋해주어야 이 파티션을 다음에 할당받는 컨슈머가 시작할 지점을 알 수 있음
리밸런스 알고리즘에 따라서 달라지게 된다.
- 조급한 리밸런스 알고리즘
- 컨슈머가 메시지 읽기는 멈춘 뒤에, 그리고 리밸런스가 시작되기 전에 호출된다.
- 협력적 리밸런스 알고리즘
- 리밸런스가 완료될 때, 컨슈머에서 할당 해제되어야 할 파티션들에 대해서만 호출된다.
- 즉, 일반적인 리밸런스 상황에서 파티션이 특정 컨슈머에서 해제될 때만 호출되므로 메서드가 호출될 때 빈 목록이 주어지는 경우는 없다.
void onPartitionsAssigned(Collection<TopicPartition> partitions)
- 파티션이 컨슈머에게 재할당 된 후에, 하지만 컨슈머가 메시지를 읽기 시작하기 전에 호출됨
- 파티션과 함께 사용할 상태를 적재하거나, 필요한 오프셋을 탐색하는 등과 같은 준비 작업 수행 시 사용
- 협력적 리밸런스를 사용할 때 컨슈머에게 새로 할당된 파티션이 없을 경우 빈 목록과 함께 호출된다.
- 컨슈머가 그룹에 문제없이 조인하려면 여기서 수행되는 모든 준비 작업은 max.poll.interval.ms 안에 완료되어야 함
default void onPartitionsLost(Collection<TopicPartition> partitions)
- 협력적 리밸런스 알고리즘 사용 시 할당된 파티션이 리밸런스 알고리즘에 의해 해제되기 전에 다른 컨슈머에게 먼저 할당된 예외적인 상황에서만 호출된다.
- 일반적인 상황에서는 onPartitionsRevoke() 가 호출된다.
- 따라서 주어지는 파티션들은 이 메서드가 호출되는 시점에서 이미 다른 컨슈머들에게 할당되어 있는 상태다.
- 이 메서드를 구현하지 않았을 경우에도 onPartitionsRevoked() 가 대신 호출된다.
- 일반적인 상황에서는 onPartitionsRevoke() 가 호출된다.
- 여기서 파티션과 함께 사용되었던 상태나 자원들을 정리해주어야 한다.
- 상태나 자원 정리 시 파티션을 새로 할당받은 컨슈머가 이미 상태를 저장했을수도 있으므로 충돌을 피하도록 주의해야 함
파티션이 해제되기 전에 onPartitionsRevoked() 를 사용하여 오프셋을 커밋하는 예시
@Slf4j
class RebalanceListener {
static Properties props = new Properties();
static {
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "broker1:9092,broker2:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "CustomerCountry");
}
private Duration timeout = Duration.ofMillis(100);
private KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
private Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();
// ConsumerRebalanceListener 구현
private class HandleRebalance implements ConsumerRebalanceListener {
// 여기서는 컨슈머가 새 파티션을 할당받았을 때 아무것도 할 필요가 없기 때문에 바로 메시지를 읽기 시작함
@Override
public void onPartitionsAssigned(Collection<TopicPartition> collection) {
}
/**
* 리밸런싱 때문에 파티션이 해제될 상황이라면 오프셋 커밋
* 할당 해제될 파티션의 오프셋 뿐 아니라 모든 파티션에 대한 오프셋 커밋 (이 오프셋들은 이미 처리된 이벤트들의 오프셋이므로 문제없음)
*/
@Override
public void onPartitionsRevoked(Collection<TopicPartition> collection) {
log.error("Lost partitions in rebalance. Commiting current offsets: {}", currentOffsets);
// 리밸런스가 진행되기 전에 모든 오프셋이 확실히 커밋되도록 commitSync() 사용
consumer.commitSync(currentOffsets);
}
}
public void commitSyncAndAsyncBeforePartitionRevoked() {
try {
// subscribe() 호출 시 ConsumerRebalanceListener 를 인수로 지정하여 컨슈머가 호출할 수 있도록 해줌
consumer.subscribe(List.of("testTopic"), new HandleRebalance());
while (true) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
log.info(
"topic: {}, partition: {}, offset: {}, customer: {}, country: {}",
record.topic(),
record.partition(),
record.offset(),
record.key(),
record.value());
currentOffsets.put(
new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1, null));
consumer.commitAsync(currentOffsets, null); // callback 을 null 로 처리
}
}
} catch (WakeupException ignore) {
} catch (Exception e) {
log.error("Unexpected error: {}", e.getMessage());
} finally {
try {
consumer.commitSync(currentOffsets);
} finally {
consumer.close();
log.info("Closed consumer and we are done.");
}
}
}
}
특정 오프셋의 레코드 읽어오기
각 파티션의 마지막으로 커밋된 오프셋부터 읽기를 시작해서 모든 메시지를 순차적으로 처리하기 위해 poll() 을 사용하였다.
- 다른 오프셋부터 읽기를 시작해야 할 경우를 위해 카프카는 다음 번 poll() 이 다른 오프셋부터 읽기를 시작하도록 하는 다양한 메서드를 제공한다.
seekToBeginning(Collection<TopicPartition> tp)은 파티션의 맨 앞에서부터 모든 메시지를 읽고자 할때 사용되고, seekToEnd(Collection<TopicPartition> tp)를 사용해서 앞의 메시지는 모두 건너뛰고 파티션의 새로 들어온 메시지부터 읽을 수 있다.
카프카 API 를 이용하여 특정한 오프셋으로 탐색(seek) 해 갈 수도 있다.
- 시간에 민감한 애플리케이션에서 처리가 늦어져서 몇 초간 메시지를 건너뛰어야 하는 경우, 파일에 데이터를 쓰는 컨슈머가 파일이 유실되어 데이터 복구를 위해 특정 과거 시점으로 되돌아가야 하는 경우
모든 파티션의 현재 오프셋을 특정한 시각에 생성된 레코드의 오프셋으로 설정하는 예시
Long oneHourEarlier =
Instant.now().atZone(ZoneId.systemDefault()).minusHours(1).toEpochSecond();
// consumer.assignment() 로 얻어온 컨슈머에 할당된 모든 파티션에 대해
// 컨슈머를 되돌리고자 하는 타임스탬프 값을 담은 맵 생성
Map<TopicPartition, Long> partitionTimestampMap =
consumer.assignment().stream().collect(Collectors.toMap(tp -> tp, tp -> oneHourEarlier));
// 브로커에 요청을 보내서 타임스탬프 인덱스에 저장된 오프셋을 리턴함
Map<TopicPartition, OffsetAndTimestamp> offsetMap = consumer.offsetsForTimes(partitionTimestampMap);
// 각 파티션의 오프셋을 앞 단계에서 리턴된 오프셋으로 재설정
for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry: offsetMap.entrySet()) {
consumer.seek(entry.getKey(), entry.getValue().offset());
}
폴링 루프를 벗어나는 방법
무한 루프에서 폴링을 수행하게 되는데 루프를 깔끔하게 탈출하는 방법에 대해 알아보자
컨슈머를 종료하고나 할 때 컨슈머가 poll() 을 기다리고 있더라도 즉시 루프를 탈출하고 싶다면 다른 스레드에서 consumer.wakeup() 을 호출해주면 되며, 메인 스레드에서 컨슈머 루프가 돌고 있다면 ShutdownHook사용할 수 있다.
- consumer.wakeup()는 다른 스레드에서 호출할 때만 안전하게 작동된다.
consumer.wakeup()을 호출하면 대기중이던 poll()은 WakeupException을 발생시키며 중단되거나, 대기중이 아닌 경우 다음번에 처음으로 poll()가 호출될 때 예외가 발생한다.
- WakeupException 을 딱히 처리해 줄 필요는 없지만 consumer.close() 는 호출해주어야 한다.
컨슈머를 닫으면 필요한 경우 오프셋을 커밋하고, 그룹 코디네이터에게 컨슈머가 그룹을 떠난다는 메시지를 전송한다.
- 이 때 컨슈머 코디네이터가 즉시 리밸런싱을 실행하므로 닫고 있던 컨슈머에게 할당되어 있던 파티션들이 그룹 안의 다른 컨슈머에게 할당될때까지 세션 타임아웃을 기다릴 필요가 없다.
메인 애플리케이션 스레드에서 돌아가는 컨슈머의 실행 루프를 종료시키는 예시
// ShutdownHook 은 별개의 스레드에서 실행되므로 폴링 루프를 탈출하기 위해 할 수 있는 것은 wakeup()을 호출하는 것 뿐이다.
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
System.out.println("Starting exit...");
movingAvg.consumer.wakeup();
try {
mainThread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}));
...
Duration timeout = Duration.ofMillis(10000); // 타임아웃을 매우 길게 설정함 10초
try {
movingAvg.consumer.subscribe(List.of(topic));
/**
* 만일 폴링 루프가 충분히 짧아서 종료되기 전에 좀 기다리는게 별로 문제가 되지 않는다면 굳이 wakeup() 을 호출해줄 필요가 없음
* 즉, 그냥 이터레이션마다 아토믹 boolean 값을 확인하는 것만으로 충분하다.
* 폴링 타임아웃을 길게 잡아주는 이유는 메시지가 조금씩 쌓이는 토픽에서 데이터를 읽어올 때 편리하기 때문이다.
* 이 방법을 사용하면 브로커가 리턴할 새로운 데이터를 가지고 있지 않은 동안 계속해서 루프를 돌면서도 더 적은 CPU 를 사용할 수 있음
*/
while (true) {
ConsumerRecords<String, String> records = movingAvg.consumer.poll(timeout);
System.out.println(System.currentTimeMillis() + " -- waiting for data...");
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s\\n", record.offset(), record.key(), record.value());
}
for (TopicPartition tp : movingAvg.consumer.assignment()) {
System.out.println("Committing offset at position:" + movingAvg.consumer.position(tp));
}
movingAvg.consumer.commitSync();
}
} catch (WakeupException ignore) {
// 다른 스레드에서 wakeup() 을 호출할 경우, 폴링 루프에서 WakeupException 발생
// 발생된 예외를 잡아줌으로써 애플리케이션이 예기치 않게 종료되지 않도록 할 수 있지만 딱히 뭔가를 추가적으로 해줄 필요는 없다.
} finally {
// 컨슈머 종료 전 닫아서 리소스 정리
movingAvg.consumer.close();
System.out.println("Closed consumer and we are done");
}
디시리얼라이저
시리얼라이저와 디시리얼라이저는 함께 쓰이는 만큼 같은 데이터 타입의 시리얼라이저와 디시리얼라이저를 묶어 놓은 org.apache.kafka.common.serialization.Serdes 클래스가 있다.
// org.apache.kafka.common.serialization.StringSerializer 리턴
Serializer<String> serializer = Serdes.String().serializer();
// org.apache.kafka.common.serialization.StringDeserializer 리턴
Deserializer<String> deserializer = Serdes.String().deserializer();
따라서 컨슈머를 생성할 때 아래처럼 사용할 수도 있다.
kafkaProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, Serdes.String().deserializer().getClass().getName());
kafkaProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, Serdes.String().deserializer().getClass().getName());
카프카에 이벤트를 쓰기 위해 사용되는 시리얼라이저와 이벤트를 읽어오기 위해 사용되는 디시리얼라이저는 서로 맞아야 한다.
- 개발자는 각 토픽에 데이터를 쓸 때 어떤 시리얼라이저를 사용했는지와 각 토픽에 사용 중인 디시리얼라이저가 읽어올 수 있는 데이터만 들어있는지 여부를 챙길 필요가 있다.
- 직렬화/역직렬화 시 Avro 와 스키마 레지스트리를 사용하면 대응하는 디시리얼라이저와 스키마를 사용하여 역직렬화할 수 있음을 보장할 수 있다.
- 프로듀서 쪽이든 컨슈머 쪽이든 호환성에 문제가 발생했을 때, 직렬화 에러가 발생한 바이트 배열을 일일이 디버깅하지 않아도 적절한 에러 메시지가 제공되기 때문에 쉽게 원인을 찾아낼 수 있다.
커스텀 시리얼라이저와 디시리얼라이저를 직접 구현하는 것은 권장하지 않는다.
- 프로듀서와 컨슈머를 너무 밀접하게 연관시키는 탓에 깨지기도 쉽고 에러가 발생할 가능성이 높다.
- JSON, Thrift, Protobuf, Avro 와 같은 표준 메시지 형식을 사용하는 것이 더 좋다.
컨슈머 그룹없이 컨슈머를 사용해야 하는 이유와 방법
컨슈머 그룹은 컨슈머들에게 파티션을 자동으로 할당해주고, 해당 그룹에 컨슈머가 추가/제거될 경우 자동으로 리밸런싱을 해준다.
컨슈머 그룹이나 리밸런스 기능이 필요없을 수 있다.
- 하지만 하나의 컨슈머가 토픽의 모든 파티션으로부터 모든 데이터를 읽어오거나, 토픽의 특정 파티션으로부터 데이터를 읽어와야 할 때
컨슈머에게 특정한 토픽과 파티션을 할당해주고, 메시지를 읽어서 처리한 후 필요할 경우 오프셋을 커밋하면 된다.
- 컨슈머가 그룹에 조인할 일이 없으니 subscribe() 메서드를 호출할 일은 없겠지만 오프셋을 커밋하려면 여전히 group.id 값은 설정해주어야 한다.
컨슈머가 어떤 파티션을 읽어야 하는지 알고 있을 경우 토픽을 구독(subscribe) 할 필요 없이 그냥 파티션을 스스로 할당받으면 된다.
- 컨슈머는 토픽을 구독(컨슈머 그룹의 일원이 된다.)하거나, 스스로 파티션을 할당받을 수 있지만 두 가지를 동시에 할 수는 없다.
컨슈머 스스로가 특정 토픽의 모든 파티션을 할당한 뒤 메시지를 읽고 처리하는 예시
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
List<TopicPartition> partitions = new ArrayList<>();
// 카프카 클러스터에 해당 토픽에 대해 사용 가능한 파티션들을 요청
// 만일 특정 파티션의 레코드만 읽어올거면 생략해도 됨
List<PartitionInfo> partitionInfos = consumer.partitionsFor("topic");
if (partitions != null) {
for (PartitionInfo partitionInfo : partitionInfos) {
partitions.add(new TopicPartition(partitionInfo.topic(), partitionInfo.partition()));
}
// 읽고자 하는 파티션이 있다면 해당 목록에 `assign()` 으로 추가
consumer.assign(partitions);
Duration timeout = Duration.ofMillis(100);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
log.info(
"topic: {}, partition: {}, offset: {}, customer: {}, country: {}",
record.topic(),
record.partition(),
record.offset(),
record.key(),
record.value());
}
consumer.commitSync();
}
}
- 리밸런싱 기능을 사용할 수 없고, 직접 파티션을 찾아야 하는 점 외엔 나머지는 크게 다르지 않다.
토픽에 새로운 파티션이 추가될 경우 컨슈머에게 알림이 오지 않는다.
- 주기적으로 consumer.partitionsFor() 를 호출하여 파티션 정보를 확인하거나, 파티션이 추가될 때마다 애플리케이션을 재시작함으로써 알림이 오지 않는 상황에 대처해 줄 필요가 있다.
'책 > 카프카 핵심 가이드' 카테고리의 다른 글
| 신뢰성 있는 데이터 전달(Kafka) (0) | 2025.01.14 |
|---|---|
| 카프카 내부 메커니즘 (1) | 2024.12.22 |
| 프로그램 내에서 코드로 카프카 관리하기 (2) | 2024.12.08 |
| 카프카 프로듀서: 카프카에 메시지 쓰기 (1) | 2024.11.09 |